카카오톡 토픽 분석9 (토픽내 단어 비교)
미션 이해
LDA에서 토픽별 단어를 비교해서 볼 수 있는 방법으로 stm 토픽들도 시각화할 수 있습니다. 아울러 stm 패키지에서 지원하는 흥미로운 기능 중 하나는 하나의 토픽내 단어들이 범주형 변수에 따라 어떻게 구분되는지도 살펴볼 수 있다는 점입니다.
최종 결과 확인
형태소 분석하기
#### 1. 분석 준비 ####
pacman::p_load(scales, ggthemes, ggridges, # 시각화 관련 패키지
PerformanceAnalytics, pheatmap, # 상관관계 시각화
forecast, # 시계열 예측 관련 패키지
RHINO, tm, RWeka, tidytext, tidystm, # 텍스트 마이닝
igraph, ggraph, tidygraph, wordcloud2, LDAvis, # 텍스트 마이닝 시각화
factoextra, # 군집분석 시각화
tidymodels, textrecipes, LiblineaR, themis, # 머신러닝
lubridate, magrittr, tidyverse) # 데이터 전처리 관련 패키지
#### 2. 데이터 전처리 ####
rdata <- read_file("../data/KakaoTalkChats.txt") %>% # txt 파일 읽어오기
strsplit("\r") %>% unlist() %>% # 같은 사람의 글은 한 줄로
gsub("\n", "", .) %>% as_tibble() %>% # 줄바꿈 없애기
filter(grepl("^\\d.*,.*:", value)) %>% # 숫자시작 , : 있는 것만
separate(value, into=c("date", "text"), sep=", ", extra="merge") %>% # 날짜와 글 분리
separate(text, into=c("name", "comment"), sep=" : ", extra="merge") # 이름과 글 내용 분리
data <- rdata %>%
rownames_to_column("id") %>% # 문서 id
mutate(date=gsub("년 ", "-", gsub("월 ", "-", gsub("일 ", " ", date)))) %>%
mutate(date=gsub("오전", "AM", gsub("오후", "PM", date))) %>% # 오전 오후 구분
mutate(date=parse_date_time(date, c("%Y-%m-%d %p %H:%M"))) %>% # 날짜 형식으로
mutate(year=year(date), quarter=quarter(date), month=month(date), # 년, 분기, 월 변수 만들기
wday=weekdays(date), yday=yday(date), hour=hour(date), # 요일, 일수, 시간 변수 만들기
ampm=ifelse(hour(date)<12, "AM", "PM")) %>% # 오전 오후 변수 만들기
select(id, year:ampm, name, comment) %>% # 주요 변수 선택
mutate(형태소=comment %>% sapply(getMorph, "NV") %>% # 명사, 동사, 형용사만 선택
sapply(paste, collapse=" ")) # 형태소 분석 결과 합치기
names_top3 <- data %>% group_by(name) %>% summarise(n=n()) %>% # 발언량이 많은
arrange(desc(n)) %>% slice(1, 2, 3) %>% pull(name) # 상위 3명 이름 저장
data <- data %>%
mutate(group=as.factor(ifelse(name %in% names_top3, "Top3", "Others"))) %>% # 그룹 지정
mutate(date=ym(paste0(year, "-", month))) %>% # 년월 지정
mutate(date=as.integer(round((date-as.Date("2019-02-01"))/(365.25/12)))) # 누적 월 계산
#### 3. 구조적 토픽모델 ####
stm_pre <- textProcessor(data$형태소, data, wordLengths = c(2,Inf), customstopwords=c("사진", "이모티콘"))
stm_out <- prepDocuments(stm_pre$documents, stm_pre$vocab, stm_pre$meta, lower.thresh=3)
k <- 13
stm_topics <- stm(stm_out$documents, stm_out$vocab, K=k, prevalence=~group+s(date),
data=stm_out$meta, seed=1000, init.type="Spectral")
데이터 전처리, 토픽분석 과정입니다. 이전 글에서 설명한 내용 그대로입니다. 다만 하나 추가된 패키지가 있는데 LDAvis가 바로 그것입니다. LDA 토픽분석 결과를 시각화하는 패키지입니다. 지난 포스트 에서는 토픽별 빈도수가 높은 단어나 배타적인 단어들을 시각화해서 토픽을 이해하려고 노력했었습니다. 이번에는 조금 더 역동적으로 토픽별 관련있는 단어들을 시각화해봅시다.
LDA처럼 토픽관련 단어 시각화
stm_likeLDA <- toLDAvisJson(mod=stm_topics, docs=stm_out$documents) # jason 파일을 만들어준다.
Encoding(stm_likeLDA) <- "unknown" # 한글 깨짐을 해결하기 위해
serVis(stm_likeLDA)
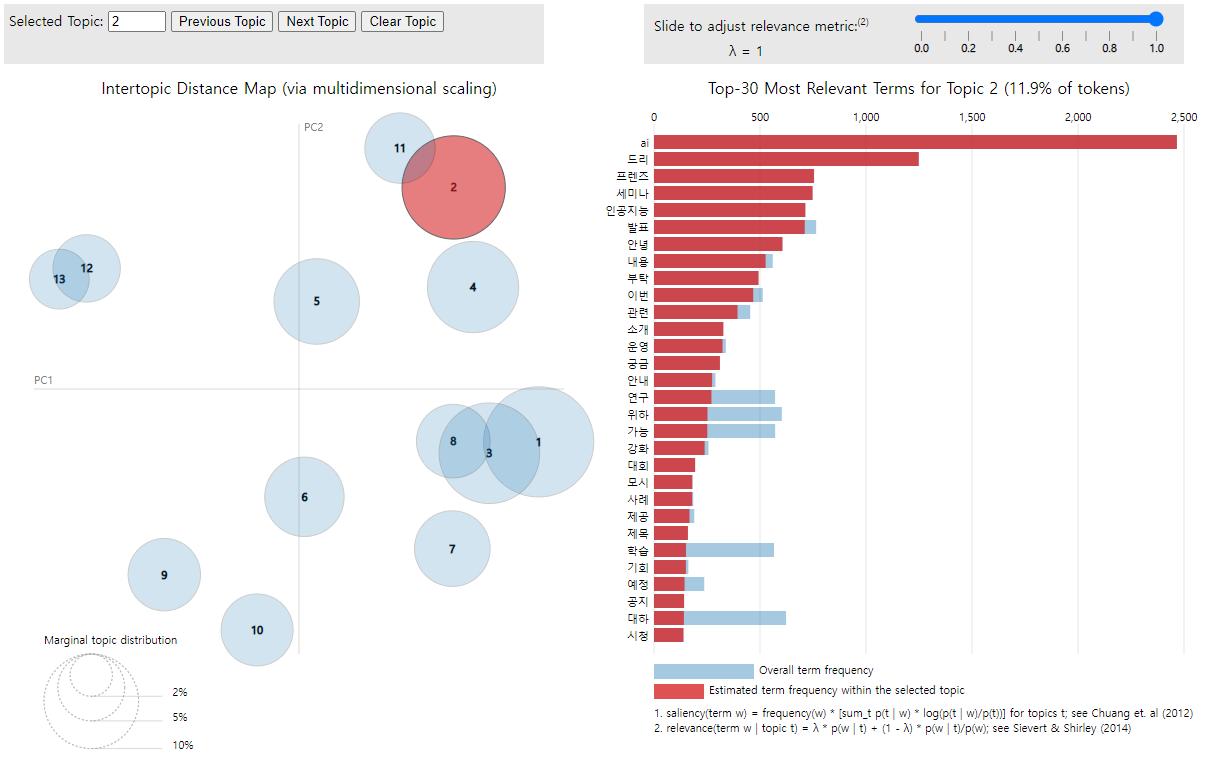
toLDAvisJson() 함수를 써서 STM 분석 결과를 json 파일 형태로 만들어 줍니다. 이를 곧바로 serVis() 함수로 시각화하면 한글이 깨집니다. 인코딩을 unknown으로 바꿔주면 한글이 깨지지 않고 잘 출력됩니다.
실제로 RStudio에서 실행하면 Viewer 탭을 통해 볼 수 있고 토픽 숫자에 마우스 커서를 올려 놓으면 해당 단어들을 볼 수 있습니다. 아이콘 중에 “Show in new window”를 클릭하면 크롬이나 엣지 브라우저로 볼 수 있습니다. 참고로 위 이미지는 토픽2에 대한 캡춰 이미지입니다.
토픽내 단어의 범주별 차이
summary(stm_content <- stm(stm_out$documents, stm_out$vocab, K=k,
prevalence=~group+s(date), content =~ group,
data=stm_out$meta, seed=1000, init.type="Spectral"))
## Beginning Spectral Initialization
## Calculating the gram matrix...
## Finding anchor words...
## ............. (중략)
## Completed M-Step (12 seconds).
## Model Converged
## A topic model with 13 topics, 23047 documents and a 5091 word dictionary.
## Topic Words:
## Topic 1: 컴퓨팅, 부류, 다과, 재택, 생각나, 하드웨어, 박사
## Topic 2: 백동천, 텅스텐, 프렌즈, 발표, 적정기술, 재방송, 학습
## Topic 3: 피자, 성함, 비효율, 자율, 출장, 삭제, 환영
## Topic 4: 스터디, daum, 가치관, 환상, 계획서, 센서, 메시지
## Topic 5: 시각화, 데이터, 수집, 사람, 무의미, 교체, 이리하
## Topic 6: 머리, 흔하, 따님, 모셔, 고정, 표준편차, 신나
## Topic 7: 예후, 아빠, 자라, 개발도상국, 담임, 군대, 기고문
## Topic 8: 금강, 정립, 강화, 특구, 팩토리, 접속자, 고오
## Topic 9: 컴터, 이것, 퇴사, 터널, 그렇, 네이처, 자르
## Topic 10: 돌잔치, 출력, 끊기, 코드, 주인, 능력, 그것
## Topic 11: 파티, 실마리, 개구리, 들이밀, 낚시꾼, 구인, 메타
## Topic 12: 축제, 인턴, 크리스마스, 극한, 가져주, 산타, 과학관
## Topic 13: 코인, 수입, 실업, 선고, 내역, 리스크, 외신
##
## Covariate Words:
## Group Others: 오렌지, 수고, 다가오, 의연, 다형, 메이커, 신경망
## Group Top3: 좌표계, 불쾌감, 애정, 원자, 전문성, 강당, 마르
##
## Topic-Covariate Interactions:
## Topic 1, Group Others: 기술사, 스코어, 업화, 특허, 친절, 골프, 부스
## Topic 1, Group Top3: kakao, 임원, 대표적, 지방, 칼럼, 따르, 과장
##
## Topic 2, Group Others: 모시, 대회, 둘레, 평가, 시청, 세미, 발현
## Topic 2, Group Top3: 금주, 학회, 과학동아, 가입, 작년, 채널, 금지
##
## Topic 3, Group Others: 간식, 플랜, 샘플링, 단체, 타임, 살인, 자바
## Topic 3, Group Top3: 논술, 비중, 왜곡, 기록, 새벽, 백신, 전환
##
## Topic 4, Group Others: 장비, 효과, 보수, 본인, 안타깝, 순환, 우수
## Topic 4, Group Top3: 우려, 업계, 이직, 아파트, 내놓, 대우, 이제
##
## Topic 5, Group Others: 왜곡, 이직, 적당, 상시, 출퇴근, 양질, 필체
## Topic 5, Group Top3: 직무, 삼성, 요구, 목적, 콘텐츠, 부서장, 본인
##
## Topic 6, Group Others: 제품, 최고, 만들, 원리, 영재, 가정, 확률
## Topic 6, Group Top3: 직원, 감시, 나가, 클라우드, 버리, 신고, 탈락
##
## Topic 7, Group Others: 임소영, 진흥원, 진로, 콘텐츠, 기상, 난리, 정보
## Topic 7, Group Top3: 주파수, 공급, 필체, 오무, 큰애, 대규모, 서울
##
## Topic 8, Group Others: 클라우드, 혁신기, 에디슨, 실장, 고등학교, 시애틀, 실력자
## Topic 8, Group Top3: 주무, 안부, 구상하, 발주자, 초대, 포함, 뉴스
##
## Topic 9, Group Others: 최진석, 깊이, 감시, 창의적, 아들, 버튼, 요소
## Topic 9, Group Top3: 보수, 감자, 충실, 살인, 경제, 늘리, 아깝
##
## Topic 10, Group Others: 액자, 애매, 신경, 초대, 오무, 아웃, 와우
## Topic 10, Group Top3: 충전, 고민하, 실패, 객체, 보행, 거르, 등급
##
## Topic 11, Group Others: 피험자, 충전, 충청, 탈락, 서비스, 흥미, 뉴스
## Topic 11, Group Top3: 상거래, 지자체, 신경, 전자, 부스, 정보, 투자
##
## Topic 12, Group Others: 주파수, 멘토, 감자, 보행, 멋있, 설명회, 산업
## Topic 12, Group Top3: 여력, 확률, 프라이, 세계, 야근, 써보, 당시
##
## Topic 13, Group Others: 물량, 대우, 퀘스트, 축소, 현대차, 상장, 접촉
## Topic 13, Group Top3: 장비, 만들, 다능, 대회, 애매, 회전, 적당
##
stm() 함수에서 content 파라미터를 group으로 설정해주면 토픽내 단어를 group별(Top3, Others)로 구분할 수 있습니다. 이를 시각화하면 다음과 같습니다.
토픽내 단어의 범주별 차이 시각화
plot(stm_content, type = "perspectives", topics = 9)

참고로 content를 설정하지 않은 stm_topics을 적용하면 에러가 납니다. 반드시 stm() 함수를 적용할 때 content를 범주형 변수로 지정해 주어야 위와 같은 시각화가 가능합니다. 이 때 등호(=) 뒤에 ~표시를 잊으면 안됩니다. prevalence와 동일한 방식으로 지정해 주어야 합니다.
토픽내 단어의 범주별 차이를 적용한 경우 토픽간 상관관계와 군집분석 결과
make.dt(stm_content, meta=stm_out$meta) %>% as_tibble() %>%
select(grep("Topic", names(.))) %>%
cor(method="spearman") %>%
pheatmap(display_numbers=T, number_color="black",
cutree_rows=4, cutree_cols=4)

content를 지정하여 토픽내 단어를 그룹내 범주별로 구별할 수 있도록 설정을 만들어 stm 분석을 하면 그 결과가 prevalence만 지정한 경우와 조금 다르게 분석 됩니다. 토픽발현 확률이 조금 달라지면서 상관계수나 군집분석 등이 모두 달라질 수 있습니다. 참고로 prevalence를 지정하지 않아도 토픽분석이 되는데 이 경우 prevalence에서 group이나 date를 지정했을 때보다 group, date와의 관련성은 떨어지게 됩니다. 이렇게도 해보고 저렇게도 해보다보니 prevalence를 지정하면 이 때 지정된 변수와의 관련성이 높은 쪽으로 분석결과가 나옵니다. content로 범주형 변수를 지정하면 범주형 변수에 의해 구분하는데 도움이 되도록 분석하기 때문에 토픽분석 결과가 달라지는 것 같습니다. 더 나아가 불용어 처리된 단어 하나에 의해서도 토픽발현 확률이나 토픽을 대변하는 단어들도 미세하게 달라지기 때문에 어떻게 토픽분석하느냐에 따라 매우 다양한 결과를 얻을 수 있습니다. 그렇다고 해서 전혀 엉뚱하게 분석되는 것은 아닙니다. 단어 몇개가 바뀌거나 단어 순위가 바뀌면서 토픽발현 확률을 뽑아보면 1~2개의 문서 순위가 바뀌는 것으로 나타나는데 그 순위 바뀜으로 인해 상관계수가 미묘하게 달라지는 것 같습니다.
아울러 content를 지정하여 STM 분석을 실시한 stm_content로는 LDA처럼 토픽 관련 단어들을 시각화할 수 없습니다.
예고
다음 글에서도 벌짓거리는 계속됩니다.
댓글남기기