카카오톡 토픽 분석8 (토픽 군집에 대한 상호작용)
미션 이해
구조적 토픽모델은 자체 함수를 이용해서 메타 데이터에 있는 다른 변수와 회귀분석을 할 수 있습니다. 다양한 변수들이 독립변수가 되고 토픽 발현확률은 종속변수가 됩니다. 이번 포스트에서는 연속형 변수에 따른 토픽 발현 확률을 어떻게 시각화하는지 살펴보겠습니다.
최종 결과 확인
형태소 분석하기
#### 1. 분석 준비 ####
pacman::p_load(scales, ggthemes, ggridges, # 시각화 관련 패키지
PerformanceAnalytics, pheatmap, # 상관관계 시각화
forecast, # 시계열 예측 관련 패키지
RHINO, tm, RWeka, tidytext, tidystm, # 텍스트 마이닝
igraph, ggraph, tidygraph, wordcloud2, # 텍스트 마이닝 시각화
factoextra, # 군집분석 시각화
tidymodels, textrecipes, LiblineaR, themis, # 머신러닝
lubridate, magrittr, tidyverse) # 데이터 전처리 관련 패키지
#### 2. 데이터 전처리 ####
rdata <- read_file("../data/KakaoTalkChats.txt") %>% # txt 파일 읽어오기
strsplit("\r") %>% unlist() %>% # 같은 사람의 글은 한 줄로
gsub("\n", "", .) %>% as_tibble() %>% # 줄바꿈 없애기
filter(grepl("^\\d.*,.*:", value)) %>% # 숫자시작 , : 있는 것만
separate(value, into=c("date", "text"), sep=", ", extra="merge") %>% # 날짜와 글 분리
separate(text, into=c("name", "comment"), sep=" : ", extra="merge") # 이름과 글 내용 분리
data <- rdata %>%
rownames_to_column("id") %>% # 문서 id
mutate(date=gsub("년 ", "-", gsub("월 ", "-", gsub("일 ", " ", date)))) %>%
mutate(date=gsub("오전", "AM", gsub("오후", "PM", date))) %>% # 오전 오후 구분
mutate(date=parse_date_time(date, c("%Y-%m-%d %p %H:%M"))) %>% # 날짜 형식으로
mutate(year=year(date), quarter=quarter(date), month=month(date), # 년, 분기, 월 변수 만들기
wday=weekdays(date), yday=yday(date), hour=hour(date), # 요일, 일수, 시간 변수 만들기
ampm=ifelse(hour(date)<12, "AM", "PM")) %>% # 오전 오후 변수 만들기
select(id, year:ampm, name, comment) %>% # 주요 변수 선택
mutate(형태소=comment %>% sapply(getMorph, "NV") %>% # 명사, 동사, 형용사만 선택
sapply(paste, collapse=" ")) # 형태소 분석 결과 합치기
names_top3 <- data %>% group_by(name) %>% summarise(n=n()) %>% # 발언량이 많은
arrange(desc(n)) %>% slice(1, 2, 3) %>% pull(name) # 상위 3명 이름 저장
data <- data %>%
mutate(group=as.factor(ifelse(name %in% names_top3, "Top3", "Others"))) %>% # 그룹 지정
mutate(date=ym(paste0(year, "-", month))) %>% # 년월 지정
mutate(date=as.integer(round((date-as.Date("2019-02-01"))/(365.25/12)))) # 누적 월 계산
#### 3. 구조적 토픽모델 ####
stm_pre <- textProcessor(data$형태소, data, wordLengths = c(2,Inf), customstopwords=c("사진", "이모티콘"))
stm_out <- prepDocuments(stm_pre$documents, stm_pre$vocab, stm_pre$meta, lower.thresh=3)
k <- 13
stm_topics <- stm(stm_out$documents, stm_out$vocab, K=k, prevalence=~group+s(date),
data=stm_out$meta, seed=1000, init.type="Spectral")
stm_removed <- setdiff(c(1:nrow(data)), stm_topics$mu$mu %>% as.data.frame() %>% names() %>% as.numeric())
데이터 전처리, 토픽분석 과정입니다. 이전 글에서 설명한 내용 그대로입니다. 이전 포스트 에서 topicCorr() 함수로 상관계수를 구하고 pheatmap() 함수로 군집분석했었습니다. 그 결과는 다음과 같습니다.
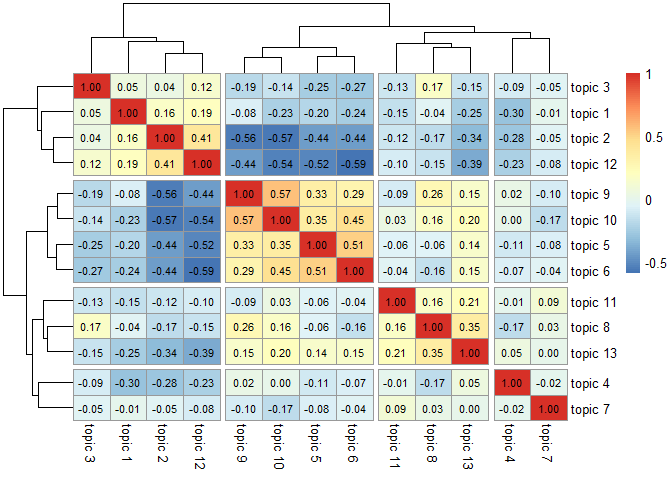
이와 동일한 작업을 조금 다르게 표현하여 동일한 결과를 얻어낼 수 있습니다.
상관계수를 이용한 군집분석
make.dt(stm_topics, meta=stm_out$meta) %>%
select(grep("Topic", names(.))) %>%
cor() %>%
pheatmap(display_numbers=T, number_color="black",
cutree_rows=4, cutree_cols=4)

make.dt() 함수는 토픽모델 만들 때 제거된 행을 제외한 나머지에 대한 토픽 발현 확률과 data의 다양한 정보를 합쳐 놓은 형태의 데이터를 만들어 줍니다. 그 중에 select() 함수와 grep() 함수를 이용하여 “Topic”이 들어간 열만 선택합니다. 그리고 cor() 함수로 상관계수를 구하고 pheatmap() 함수로 군집분석을 실시하면 위와 같은 결과를 얻을 수 있습니다.
그런데 토픽이 13개나 되기 때문에 어떤 글이 특정 토픽이 될 가능성이 매우 낮은 것이 일반적일 수밖에 없다. 결국 토픽발현 확률을 보면 정규분포를 그리지 않습니다.
상관계수 및 도수 분포표 보기
make.dt(stm_topics, meta=stm_out$meta) %>%
select(grep("Topic", names(.))) %>%
chart.Correlation()

도수 분포표를 보면 왼쪽으로 매우 많이 치우진 형태를 보입니다. 따라서 pearson 상관계수를 구하기 보다는 spearman 상관계수를 구하는 것이 더 타당합니다. topicCorr() 함수에서는 spearman 상관계수를 출력할 수 없었는데 make.dt() 함수로 토픽 발현 확률을 끄집어 내면 얼마든지 spearman 상관계수를 구할 수 있습니다.
spearman 상관계수로 군집화하기
make.dt(stm_topics, meta=stm_out$meta) %>%
select(grep("Topic", names(.))) %>%
cor(method="spearman") %>%
pheatmap(display_numbers=T, number_color="black",
cutree_rows=4, cutree_cols=4)

pearson 상관계수로 군집분석한 결과와 아주 조금 차이가 있습니다. 토픽 두 어개의 군집이 바뀌었습니다. 그 이외에도 토픽간 상관계수가 더 커진 것을 알 수 있습니다. 비슷한 토픽들끼리 더 잘 묶여진 것을 확인할 수 있습니다.
spearman 상관계수는 cor() 함수에 method를 spearman으로 입력하면 구할 수 있습니다.
위와 같이 spearman 상관계수를 이용해서 군집분석한 결과를 반영하여 비슷한 토픽끼리 묶어보겠습니다.
월별, 그룹별 토픽발현확률 구하기
stm_data <- make.dt(stm_topics, meta=stm_out$meta) %>%
rename_all(~str_remove(.,"opic")) %>% as_tibble() %>%
mutate(topic1=(T2+T12+T1+T3), topic2=(T8+T7+T11),
topic3=(T5+T6+T9+T10), topic4=(T4+T13)) %>%
group_by(date, group) %>%
summarise(topic1=mean(topic1), topic2=mean(topic2),
topic3=mean(topic3), topic4=mean(topic4)) %>%
arrange(group) %>% ungroup() %>%
mutate(date=rep(seq(as.Date("2019-02-01"), as.Date("2021-12-01"), length.out=36), 2))
월별, 그룹별 토픽발현확률의 평균을 구하여 월의 흐름에 따른 토픽 발현확률을 분석하고자 합니다.
토픽 발현 확률을 합할 때 Topic3+Topic1 등과 같이 긴 이름을 쓰는 것이 귀찮아서 rename_all() 함수를 써서 열 이름에서 “opic”을 지웠습니다. 그러면 T3+T1 등과 같이 표현할 수 있기 때문입니다. 열 이름(column name)의 첫 글자는 문자이어야 하기 때문에 T는 삭제하지 않았습니다. as_tibble() 함수로 만들어서 제대로 작동하는지 확인한 후 각각의 그룹에 해당되는 토픽들끼리 합해줍니다. 어차피 하나의 문서가 가질 수 있는 확률의 합은 1이기 때문에 비슷한 군집끼리의 토픽 발현확률을 모두 더해서 표현해도 절대 1을 넘기지 않기 때문에 평균을 구하지 않고 합으로 계산하였습니다. group_by() 함수를 써서 월별 날짜와 그룹별로 평균 토픽발현 확률의 평균을 summarise() 함수를 이용하여 구합니다. arrange() 함수를 이용하여 group별로 정렬합니다. 그러면 Others끼리 Top3끼리 묶입니다. 그리고 rep() 함수와 seq() 함수를 이용하여 날짜 형태의 데이터로 바꿔줍니다. 회귀분석에서는 날짜 형태의 데이터도 분석이 가능하기 때문에 상관 없습니다.
상호작용 확인하기
summary(lm(topic3~group*date, stm_data))
##
## Call:
## lm(formula = topic3 ~ group * date, data = stm_data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.082485 -0.025898 -0.001132 0.025950 0.089467
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.905e+00 3.414e-01 -5.580 4.54e-07 ***
## groupTop3 -8.006e-01 4.828e-01 -1.658 0.1019
## date 1.191e-04 1.851e-05 6.437 1.44e-08 ***
## groupTop3:date 4.642e-05 2.617e-05 1.774 0.0806 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.03408 on 68 degrees of freedom
## Multiple R-squared: 0.7137, Adjusted R-squared: 0.701
## F-statistic: 56.49 on 3 and 68 DF, p-value: < 2.2e-16
상호작용 효과가 통계적으로 유의한지 살펴보았는데 0.05보다 크게 나왔습니다. 95% 신뢰수준에서는 통계적으로 유의하지 않지만 90% 신뢰수준에서는 통계적으로 유의하다고 판단할 수도 있습니다. 대략 상호작용 효과가 있다고 볼 수도 있다는 뜻입니다.
상호작용 효과 시각화1
stm_data %>%
ggplot(aes(date, topic3, group=group, color=group)) +
geom_point() +
geom_smooth(method="lm") +
scale_x_date(date_breaks = "6 month", date_labels = "%Y-%m") +
theme_bw() +
theme(legend.position=c(0.2, 0.85)) +
scale_color_manual(values=c("tomato", "royalblue")) +
labs(x="time", y="Expected Topic Proportion", title="토픽9 그룹에 대한 상호작용 효과")

앞에서 상호작용 효과를 시각화했던 것과 같은 방법으로 시각화하였습니다. 회귀분석 결과를 선으로 표현하는 함수가 geom_smooth() 입니다. method를 lm으로 입력하면 선형회귀분석 결과를 시각화합니다. 평활법으로 표현하려면 다음과 같이 코드를 수정하면 됩니다.
상호작용 효과 시각화2
stm_data %>%
ggplot(aes(date, topic3, group=group, color=group)) +
geom_point() +
geom_smooth() +
scale_x_date(date_breaks = "6 month", date_labels = "%Y-%m") +
theme_bw() +
theme(legend.position=c(0.2, 0.85)) +
scale_color_manual(values=c("tomato", "royalblue")) +
labs(x="time", y="Expected Topic Proportion", title="토픽9 그룹에 대한 상호작용 효과")
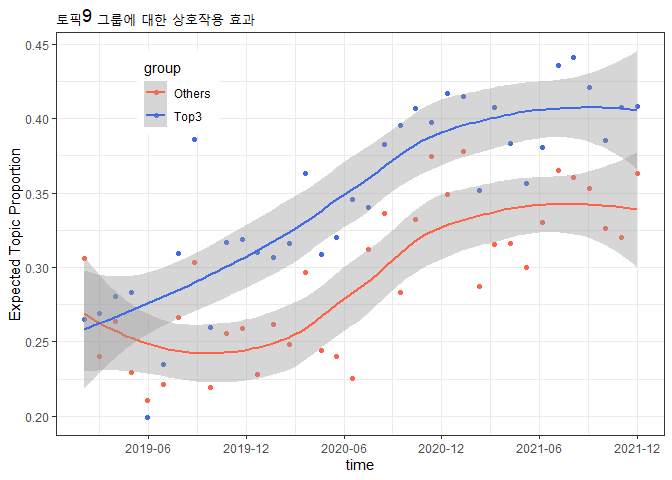
geom_smooth() 함수에서 method 파라미터만 지우면 됩니다. 이와 같은 방법으로 토픽2가 속한 그룹의 토픽 발현 확률이나 토픽4가 속한 그룹의 토픽 발현 확률에 대해서도 회귀분서이나 상호작용 효과 등을 분석할 수 있습니다.
예고
다음 글에서도 벌짓거리는 계속됩니다.
댓글남기기