카카오톡 토픽 분석3 (토픽간 상관관계와 군집분석)
미션 이해
구조적 토픽모델은 LDA와 달리 토픽간 상관관계를 무시하지 않습니다. 그러다보니 토픽간 상관관계가 있고 그에 따라 비슷한 토픽들끼리 묶어서 군집화할 수도 있습니다. 토픽간 상관계수를 구하고 이를 바탕으로 다양한 방법으로 군집화해서 살펴보도록 하겠습니다.
최종 결과 확인
형태소 분석하기
#### 1. 분석 준비 ####
pacman::p_load(scales, ggthemes, ggridges, # 시각화 관련 패키지
PerformanceAnalytics, pheatmap, # 상관관계 시각화
forecast, # 시계열 예측 관련 패키지
RHINO, tm, RWeka, tidytext, tidystm, # 텍스트 마이닝
igraph, ggraph, tidygraph, wordcloud2, # 텍스트 마이닝 시각화
factoextra, # 군집분석 시각화
tidymodels, textrecipes, LiblineaR, themis, # 머신러닝
lubridate, magrittr, tidyverse) # 데이터 전처리 관련 패키지
#### 2. 데이터 전처리 ####
rdata <- read_file("../data/KakaoTalkChats.txt") %>% # txt 파일 읽어오기
strsplit("\r") %>% unlist() %>% # 같은 사람의 글은 한 줄로
gsub("\n", "", .) %>% as_tibble() %>% # 줄바꿈 없애기
filter(grepl("^\\d.*,.*:", value)) %>% # 숫자시작 , : 있는 것만
separate(value, into=c("date", "text"), sep=", ", extra="merge") %>% # 날짜와 글 분리
separate(text, into=c("name", "comment"), sep=" : ", extra="merge") # 이름과 글 내용 분리
data <- rdata %>%
rownames_to_column("id") %>% # 문서 id
mutate(date=gsub("년 ", "-", gsub("월 ", "-", gsub("일 ", " ", date)))) %>%
mutate(date=gsub("오전", "AM", gsub("오후", "PM", date))) %>% # 오전 오후 구분
mutate(date=parse_date_time(date, c("%Y-%m-%d %p %H:%M"))) %>% # 날짜 형식으로
mutate(year=year(date), quarter=quarter(date), month=month(date), # 년, 분기, 월 변수 만들기
wday=weekdays(date), yday=yday(date), hour=hour(date), # 요일, 일수, 시간 변수 만들기
ampm=ifelse(hour(date)<12, "AM", "PM")) %>% # 오전 오후 변수 만들기
select(id, year:ampm, name, comment) %>% # 주요 변수 선택
mutate(형태소=comment %>% sapply(getMorph, "NV") %>% # 명사, 동사, 형용사만 선택
sapply(paste, collapse=" ")) # 형태소 분석 결과 합치기
names_top3 <- data %>% group_by(name) %>% summarise(n=n()) %>% # 발언량이 많은
arrange(desc(n)) %>% slice(1, 2, 3) %>% pull(name) # 상위 3명 이름 저장
data <- data %>%
mutate(group=as.factor(ifelse(name %in% names_top3, "Top3", "Others"))) %>% # 그룹 지정
mutate(date=ym(paste0(year, "-", month))) %>% # 년월 지정
mutate(date=as.integer(round((date-as.Date("2019-02-01"))/(365.25/12)))) # 누적 월 계산
#### 3. 구조적 토픽모델 ####
stm_pre <- textProcessor(data$형태소, data, wordLengths = c(2,Inf), customstopwords=c("사진", "이모티콘"))
stm_out <- prepDocuments(stm_pre$documents, stm_pre$vocab, stm_pre$meta, lower.thresh=3)
k <- 13
stm_topics <- stm(stm_out$documents, stm_out$vocab, K=k, prevalence=~group+s(date),
data=stm_out$meta, seed=1000, init.type="Spectral")
stm_removed <- setdiff(c(1:nrow(data)), stm_topics$mu$mu %>% as.data.frame() %>% names() %>% as.numeric())
데이터 전처리, 토픽분석 과정입니다. 이전 글에서 설명한 내용 그대로입니다.
토픽별 상관계수 구하기
stm_cor <- topicCorr(stm_topics)
rownames(stm_cor$cor) <- colnames(stm_cor$cor) <- paste0("topic ", 1:13)
stm_cor$cor
## topic 1 topic 2 topic 3 topic 4 topic 5
## topic 1 1.00000000 0.16013977 0.05204654 -0.30494478 -0.20132181
## topic 2 0.16013977 1.00000000 0.04129762 -0.27687813 -0.43666228
## topic 3 0.05204654 0.04129762 1.00000000 -0.08883606 -0.25217692
## topic 4 -0.30494478 -0.27687813 -0.08883606 1.00000000 -0.10666416
## topic 5 -0.20132181 -0.43666228 -0.25217692 -0.10666416 1.00000000
## topic 6 -0.24425719 -0.44090704 -0.26502330 -0.07247495 0.50714745
## topic 7 -0.01132980 -0.04894104 -0.05066782 -0.01612474 -0.07526182
## topic 8 -0.03692728 -0.16668043 0.16686015 -0.17180747 -0.05712027
## topic 9 -0.08230014 -0.55874244 -0.19156810 0.01873586 0.33408445
## topic 10 -0.23408024 -0.56939970 -0.14414593 0.00000000 0.35200523
## topic 11 -0.15254907 -0.12085558 -0.12648059 -0.01134116 -0.06160662
## topic 12 0.19378518 0.40951890 0.12485291 -0.22944632 -0.52418624
## topic 13 -0.25291008 -0.33604126 -0.14526370 0.05246792 0.14156973
## topic 6 topic 7 topic 8 topic 9 topic 10
## topic 1 -0.24425719 -0.01132980 -0.03692728 -0.08230014 -0.2340802
## topic 2 -0.44090704 -0.04894104 -0.16668043 -0.55874244 -0.5693997
## topic 3 -0.26502330 -0.05066782 0.16686015 -0.19156810 -0.1441459
## topic 4 -0.07247495 -0.01612474 -0.17180747 0.01873586 0.0000000
## topic 5 0.50714745 -0.07526182 -0.05712027 0.33408445 0.3520052
## topic 6 1.00000000 -0.03860493 -0.15570662 0.29191995 0.4451840
## topic 7 -0.03860493 1.00000000 0.02604494 -0.09836299 -0.1716424
## topic 8 -0.15570662 0.02604494 1.00000000 0.26015368 0.1593166
## topic 9 0.29191995 -0.09836299 0.26015368 1.00000000 0.5674070
## topic 10 0.44518400 -0.17164240 0.15931663 0.56740701 1.0000000
## topic 11 -0.04003242 0.09469132 0.15519984 -0.08510389 0.0315157
## topic 12 -0.59399434 -0.08420883 -0.14720422 -0.43924693 -0.5371137
## topic 13 0.15078991 0.00000000 0.34851525 0.15468786 0.2037268
## topic 11 topic 12 topic 13
## topic 1 -0.15254907 0.19378518 -0.25291008
## topic 2 -0.12085558 0.40951890 -0.33604126
## topic 3 -0.12648059 0.12485291 -0.14526370
## topic 4 -0.01134116 -0.22944632 0.05246792
## topic 5 -0.06160662 -0.52418624 0.14156973
## topic 6 -0.04003242 -0.59399434 0.15078991
## topic 7 0.09469132 -0.08420883 0.00000000
## topic 8 0.15519984 -0.14720422 0.34851525
## topic 9 -0.08510389 -0.43924693 0.15468786
## topic 10 0.03151570 -0.53711374 0.20372675
## topic 11 1.00000000 -0.09868799 0.21356023
## topic 12 -0.09868799 1.00000000 -0.39010225
## topic 13 0.21356023 -0.39010225 1.00000000
topicCorr() 함수를 이용하여 상관계수를 구합니다. 리스트 형태로 결과가 나오기 때문에 상관계수를 구한 stm_cor$cor에서 그 결과를 확인할 수 있습니다. 문제는 토픽명이 없는 형태로 제공이 되기 때문에 행과 열의 이름을 붙여 넣어야 합니다. Topic 1, Topic2 와 같은 방식으로 Topic 1에서 Topic 13까지 paste0() 함수로 만들어서 colum name과 row name을 바꿔줍니다. 행과 열의 이름을 붙여 넣어주면 위와 같은 결과를 볼 수 있습니다.
토픽별 상관계수와 군집화
pheatmap(stm_cor$cor,
display_numbers=T, number_color="black",
cutree_rows=4, cutree_cols=4)
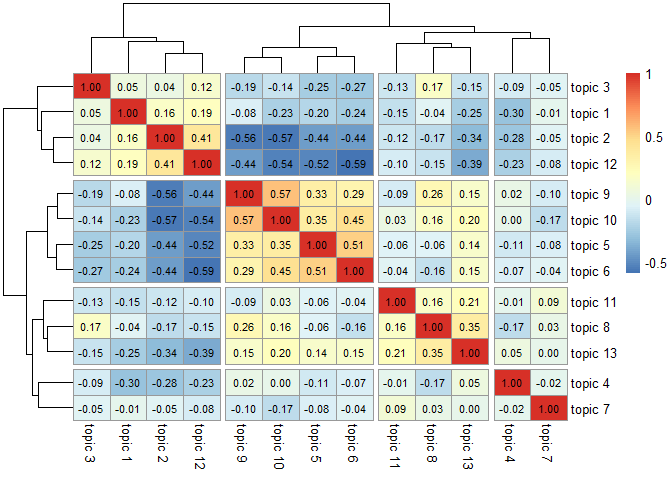
토픽간의 상관관계를 바탕으로 비슷한 토픽들끼리 군집분석을 실시할 수 있습니다.
pheatmap 패키지에서 지원하는 pheatmap() 함수의 cutree_rows와 cutree_cols 파라미터로 적절한 수의 군집을 구분하여 시각화할 수 있습니다. 여기에서는 4개로 구분하였습니다만 적게는 2개로 분류할 수도 있고 3개도 가능할 것 같습니다.
계층적 군집분석
stm_hc <- hclust(dist(scale(stm_cor$cor), method="euclidian"), "ward.D")
fviz_dend(stm_hc, k=4, palette="Dark2", rect=T)
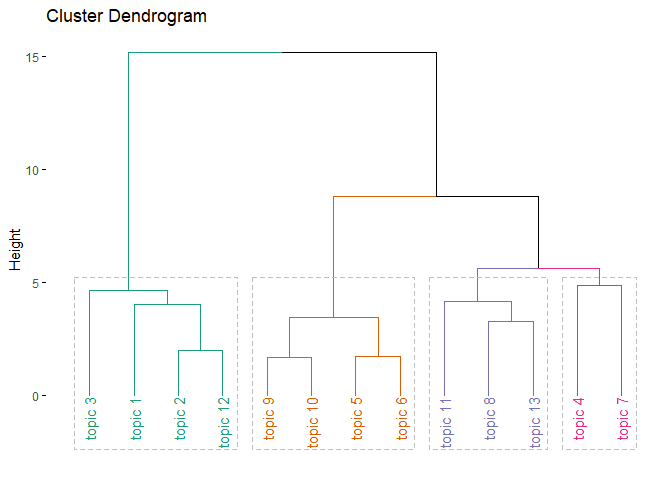
유클리디안 거리를 구하여 “ward.D” 방식으로 군집분석을 실시한 결과를 stm_hc에 저장합니다.
factoextra 패키지의 fviz_dend() 함수를 이용하여 계층적 군집분석 결과를 시각화합니다. k값으로 적절한 군집의 수를 지정합니다. rect 파라미터를 TRUE로 지정하면 군집별로 묶여져서 표현됩니다. 통계적으로 유의한지의 여부나 상관계수보다는 변수들간의 군집관계를 확인할 때 주로 사용합니다. 앞에서와 마찬가지로 4개로 설정하였습니다만 pheatmap 분석 결과와 마찬가지로 크게는 2개도 가능하고 3개도 가능할 것 같습니다.
토픽별 상관관계 시각화
plot(topicCorr(stm_topics, cutoff = 0.1), vertex.color = as.factor(cutree(stm_hc, k=4)))

topicCorr() 함수로 토픽간 상관관계를 구하는데 cutoff를 0.1로 설정하여 상관계수가 0.1이 안 되는 경우 토픽간 단절시키는 방식으로 시각화 하였습니다. 계층적 군집분석에 의한 군집을 색으로 표현하였습니다.
차원축소 군집분석
scale(stm_cor$cor) %>% kmeans(4) %>% fviz_cluster(scale(stm_cor$cor))

kmeans로 군집분석한 결과를 주성분 분석(PCA)로 차원을 축소하여 시각화한 결과입니다. x축과 y축은 각각 제1주성분과 제2주성분에 해당되며 제1주성분은 전체 변동의 48.7%를 설명합니다. 제2주성분은 12.8%로 두 축으로만 60% 정도를 설명합니다. 나쁘지 않은 수치입니다.
이 이외에도 매우 많은 군집분석 방법이 있습니다. 어떤 알고리즘과 방법을 적용하느냐에 따라 군집은 서로 다르게 묶일 수 있습니다. 무엇을 선택할지는 분석하는 사람 마음입니다. 실제 데이터를 가장 잘 설명한다고 생각되는 방법을 택하면 됩니다.
예고
다음 글에서 다양한 변수에 따른 토픽 발현 확률을 시각화 해보도록 하겠습니다.
댓글남기기