카카오톡 토픽 분석2 (토픽명 정하기)
미션 이해
구조적 토픽모델로 분석한 토픽을 보다 구체화 하고자 합니다. 해당 토픽에서 빈번하게 사용한 단어는 무엇인지 시각화합니다. 구조적 토픽모델에서는 단어를 서로 공유하기 때문에 때로는 빈도수가 높은 단어를 공유할 수도 있습니다. 이 때는 해당 토픽에서는 빈도수가 높지만 다른 토픽에서는 빈도수 상대적으로 낮은 단어(배타적인 단어)가 중요하게 됩니다. 이러한 배터적인 단어도 함께 시각화하고자 합니다. 마지막으로 해당 토픽의 대표 문서의 내용을 읽어보면서 적절한 토픽명을 정하면 됩니다.
최종 결과 확인
형태소 분석하기
#### 1. 분석 준비 ####
pacman::p_load(scales, ggthemes, ggridges, # 시각화 관련 패키지
PerformanceAnalytics, pheatmap, # 상관관계 시각화
forecast, # 시계열 예측 관련 패키지
RHINO, tm, RWeka, tidytext, tidystm, # 텍스트 마이닝
igraph, ggraph, tidygraph, wordcloud2, # 텍스트 마이닝 시각화
factoextra, # 군집분석 시각화
tidymodels, textrecipes, LiblineaR, themis, # 머신러닝
lubridate, magrittr, tidyverse) # 데이터 전처리 관련 패키지
#### 2. 데이터 전처리 ####
rdata <- read_file("../data/KakaoTalkChats.txt") %>% # txt 파일 읽어오기
strsplit("\r") %>% unlist() %>% # 같은 사람의 글은 한 줄로
gsub("\n", "", .) %>% as_tibble() %>% # 줄바꿈 없애기
filter(grepl("^\\d.*,.*:", value)) %>% # 숫자시작 , : 있는 것만
separate(value, into=c("date", "text"), sep=", ", extra="merge") %>% # 날짜와 글 분리
separate(text, into=c("name", "comment"), sep=" : ", extra="merge") # 이름과 글 내용 분리
data <- rdata %>%
rownames_to_column("id") %>% # 문서 id
mutate(date=gsub("년 ", "-", gsub("월 ", "-", gsub("일 ", " ", date)))) %>%
mutate(date=gsub("오전", "AM", gsub("오후", "PM", date))) %>% # 오전 오후 구분
mutate(date=parse_date_time(date, c("%Y-%m-%d %p %H:%M"))) %>% # 날짜 형식으로
mutate(year=year(date), quarter=quarter(date), month=month(date), # 년, 분기, 월 변수 만들기
wday=weekdays(date), yday=yday(date), hour=hour(date), # 요일, 일수, 시간 변수 만들기
ampm=ifelse(hour(date)<12, "AM", "PM")) %>% # 오전 오후 변수 만들기
select(id, year:ampm, name, comment) %>% # 주요 변수 선택
mutate(형태소=comment %>% sapply(getMorph, "NV") %>% # 명사, 동사, 형용사만 선택
sapply(paste, collapse=" ")) # 형태소 분석 결과 합치기
names_top3 <- data %>% group_by(name) %>% summarise(n=n()) %>% # 발언량이 많은
arrange(desc(n)) %>% slice(1, 2, 3) %>% pull(name) # 상위 3명 이름 저장
data <- data %>%
mutate(group=as.factor(ifelse(name %in% names_top3, "Top3", "Others"))) %>% # 그룹 지정
mutate(date=ym(paste0(year, "-", month))) %>% # 년월 지정
mutate(date=as.integer(round((date-as.Date("2019-02-01"))/(365.25/12)))) # 누적 월 계산
#### 3. 구조적 토픽모델 ####
stm_pre <- textProcessor(data$형태소, data, wordLengths = c(2,Inf), customstopwords=c("사진", "이모티콘"))
stm_out <- prepDocuments(stm_pre$documents, stm_pre$vocab, stm_pre$meta, lower.thresh=3)
k <- 13
stm_topics <- stm(stm_out$documents, stm_out$vocab, K=k, prevalence=~group+s(date),
data=stm_out$meta, seed=1000, init.type="Spectral")
stm_removed <- setdiff(c(1:nrow(data)), stm_topics$mu$mu %>% as.data.frame() %>% names() %>% as.numeric())
데이터 전처리, 적절한 토픽수 결정, 토픽분석 과정입니다. 적절한 토픽수 결정은 이전 글로 대체합니다.
토픽별 빈도수 높은 단어 표시1
plot(stm_topics, type="summary", labeltype="prob", n=5, xlim=c(0, 0.45))

토픽 발현확률이 높은 것부터 순서대로 정렬하고 각각의 토픽에서 빈도수가 많은 단어 5개를 시각화합니다. 선의 길이가 평균 토픽 발현 확률입니다. 선의 길이가 가장 긴 토픽 12의 발현 확률이 가장 크고 길이가 가장 짧은 토픽 8의 발현 확률이 가장 작습니다.
xlim은 x축의 범위를 설정합니다. 범위를 조정해서 글자가 잘 보이도록 해야 합니다. 0에서 0.45까지 설정하면 빈도수가 높은 단어가 적절하게 잘 보입니다. 간결해서 논문에도 자주 삽입되는 그래프이지만 볼품없어 보이기도 합니다. 조금 더 세련되고 그럴 듯하게 보이기 위해 다음과 같이 표현하기도 합니다.
토픽별 빈도수 높은 단어 표시2
tidy(stm_topics) %>% group_by(topic) %>% slice_max(beta, n=10) %>% ungroup() %>%
mutate(topic=paste0("Topic ", topic)) %>%
ggplot(aes(beta, reorder_within(term, beta, topic), fill = topic)) +
geom_col(show.legend = FALSE) +
facet_wrap(~topic, ncol=3, scales = "free_y") +
scale_y_reordered() +
labs(x = NULL, y = expression(beta), title = "토픽별 빈도수가 높은 단어들")
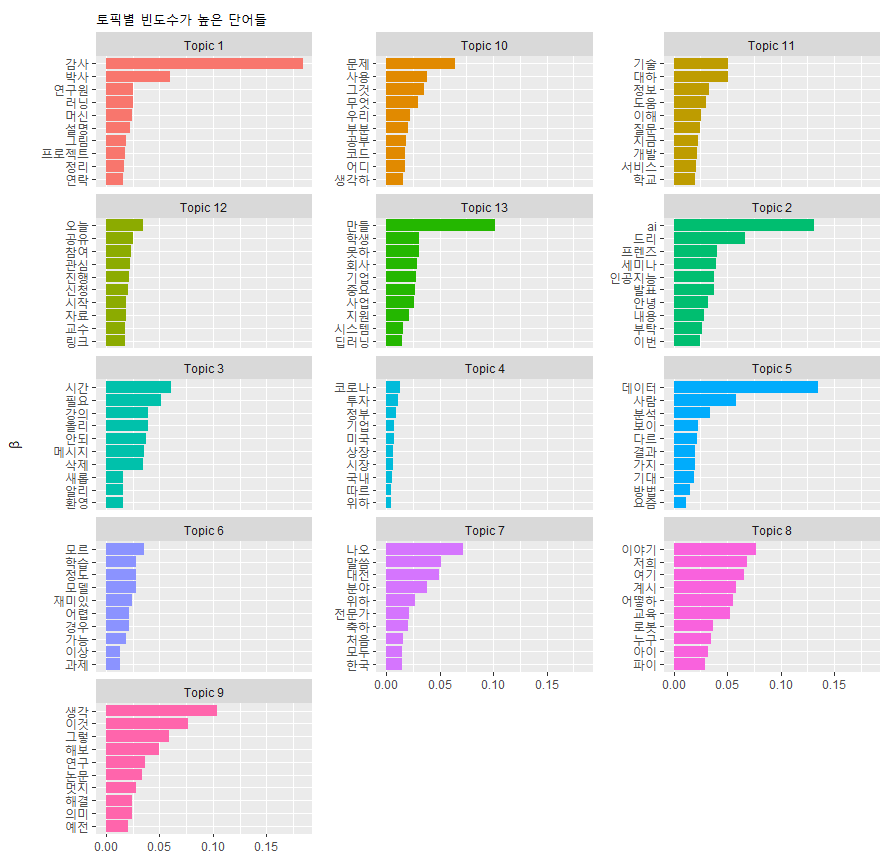
토픽의 개수가 많아서 산만해 보입니다. 토픽이 4~6개 정도 되는 경우 매우 그럴듯하게 보입니다.
tidy() 함수를 적용하면 토픽별 단어(term)와 빈도수를 대변하는 값(beta)를 얻을 수 있습니다. topic을 그룹으로 설정하여 최대 10개만 잘라내고 ungroup() 합니다. 토픽은 숫자로만 이루어져 있기 때문에 숫자 앞에 “Topic”이라는 글자를 붙입니다. ggplot() 함수로 시각화합니다.
reorder_within() 함수는 토픽별로 단어를 beta 순서로 정렬하는 역할을 합니다. facet_wrap() 함수는 토픽별로 단어와 beta값을 그래프로 그리도록 하며 ncol로 몇 개의 열로 그래프를 시각화할지를 정합니다. scale_y_reordered() 함수는 reorder_within() 함수 적용할 때 단어에 붙은 토픽을 제거해주는 역할을 합니다.
토픽별 배타적인 단어 표시
plot(stm_topics, type="summary", labeltype="frex", n=5, xlim=c(0, 0.45))

frex는 해당 토픽에서는 빈도수가 높지만 다른 토픽에서는 그렇지 않은 배타적인 단어를 가리킵니다. 이 역시 5개를 시각화합니다.
토픽명을 지정할 때 주로 사용하는 빈도수가 높은 단어와 토픽을 구별하는 배타적인 단어를 주로 참고합니다. 그런데 각각 시각화하면 통합적으로 검토하기 힘들어서 한꺼번에 표현하는 방법을 다음과 같이 구현했습니다.
토픽별 대표 단어 표시
stm_word_function <- function(model=stm_topics, k=13, n=7){
for(j in 1:k){
porb <- labelTopics(model, 1:k, n)$prob[j, ]
frex <- labelTopics(model, 1:k, n)$frex[j, ]
ifelse(identical(intersect(porb, frex), character(0)),
terms <- porb %>% paste0(collapse = ", "),
terms <- setdiff(porb, frex) %>% paste0(collapse = ", ") %>%
append(paste0("(", intersect(porb, frex), ")", collapse = ", ")) %>%
paste0(collapse=", "))
ifelse(j==1,
result <- data.frame(topic=1, terms=terms),
result <- result %>%
bind_rows(data.frame(topic=j, terms=terms))
)
}
result <- result %>% mutate(topic=as.factor(topic))
return(result)
}
(stm_word <- stm_word_function(stm_topics, k=13, n=7))
## topic terms
## 1 1 감사, 연구원, 설명, 그림, (박사), (러닝), (머신)
## 2 2 ai, 드리, 인공지능, 발표, (프렌즈), (세미나), (안녕)
## 3 3 시간, 필요, 올리, 안되, (강의), (메시지), (삭제)
## 4 4 코로나, 정부, 기업, 시장, (투자), (미국), (상장)
## 5 5 사람, 분석, 보이, 다르, 결과, 가지, (데이터)
## 6 6 학습, 정도, 모델, 어렵, 경우, (모르), (재미있)
## 7 7 나오, 분야, 위하, 전문가, (말씀), (대전), (축하)
## 8 8 여기, 어떻하, 로봇, (이야기), (저희), (계시), (교육)
## 9 9 해보, 연구, (생각), (이것), (그렇), (논문), (멋지)
## 10 10 문제, 사용, 무엇, 우리, 부분, 공부, (그것)
## 11 11 기술, 대하, 정보, 이해, 지금, (도움), (질문)
## 12 12 오늘, 공유, 참여, 관심, 진행, 신청, 시작
## 13 13 못하, 회사, 기업, 중요, 사업, (만들), (학생)
배타적인 단어들 중에 빈도수가 높은 단어들은 해당 토픽의 중요한 특징이라고 볼 수 있습니다. 따라서 빈도수가 높은 단어들 목록에서 배타적인 단어가 있는 경우 해당 단어를 괄호로 묶어서 나타냈습니다.
labelTopics() 함수는 토픽별 빈도수가 높은 단어나 배타적인 단어를 출력합니다. intersect() 함수는 교집합을 의미하며 교집합이 없는 경우에는 identical() 함수 적용 결과 character(0)이 출력됩니다. 이 경우에는 빈도수가 높은 단어들만 “,”로 묶어줍니다. 그렇지 않은 경우 setdiff() 함수로 빈도수가 높은 단어에서 배타적인 단어를 제외해서 “,”를 붙입니다. 그 뒤에 append() 함수를 써서 intersect() 함수로 구한 교집합에 해당하는 단어에 괄호를 붙여 역시 “,”로 이어줍니다.
j는 토픽을 가리키는 것으로 첫번째 토픽은 dataframe을 만들어 주고, 두 번째 토픽부터는 행을 추가하는 방식으로 모든 토픽에 대한 빈도수가 높은 단어와 그 중 배타적인 단어를 구분하여 정리하도록 합니다.
마지막으로 topic을 factor로 지정하여 저장한 후 출력합니다. 이렇게 정의된 함수에 토픽과 토픽의 수, 그리고 표현할 단어의 수를 지정해서 stm_word에 저장합니다.
토픽별 대표 단어 시각화
tidy(stm_topics, matrix="gamma") %>% # 문서별 토픽발현 확률 추출
group_by(topic) %>% summarise(gamma=round(mean(gamma), 3)) %>% # 토픽별로 평균값 계산
mutate(topic=as.factor(topic)) %>% # 토픽을 factor로 지정
left_join(stm_word) %>% # 토픽별 대표 단어 합치기
mutate(terms=paste0(" [", gamma*100, "%] ", terms)) %>% # 토픽별 발현 확률 표시
ggplot(aes(gamma, reorder(topic, gamma), label=terms, fill=topic)) + # 시각화
geom_col(show.legend = FALSE, alpha=0.7) +
geom_text(aes(x=0), hjust=-0.01, nudge_y=0.05, size=4) +
coord_cartesian(xlim = c(0, 0.2)) +
theme_few() +
theme(plot.title = element_text(size=17)) +
labs(x = "토픽 발현 확률", y = "토픽", title = "토픽별 발현 확률과 토픽별 빈도수가 높은 단어들",
subtitle = "괄호 안의 단어는 토픽을 구분하는 배타적인 단어") +
scale_x_continuous(labels = percent)

토픽별 평균 발현 확률과 토픽별 빈도수가 높은 단어들 중 배타적인 단어를 시각화합니다.
tidy() 함수에 matrix 파라미터를 gamma로 지정하면 문서별 토픽 발현 확률을 추출할 수 있습니다. 디폴트는 beta 값입니다. 토픽별 발현 확률의 평균을 구한 다음 앞에서 만든 stm_word를 merge() 함수를 이용하여 합칩니다. 토픽별 발현확률을 []로 묶어서 표시해주고 이를 시각화합니다. 이렇게 하면 토픽별 빈도수 높은 단어 표시1에서 얻었던 그래프와 유사한 형태를 얻을 수 있습니다. 더 나은 점은 빈도수가 높은 단어들 중에서 문서의 특성을 대변해주는 배타적인 단어가 괄호로 표현되었다는 것입니다.
토픽별 대표 문서 읽기1
findThoughts(stm_topics, texts=slice(data, -c(stm_removed)) %>% pull(comment), n=5, topics=2)$docs[[1]]
## [1] "톡게시판 '공지': AI프렌즈 제60회 세미나를 안내합니다.(https://aifrenz.github.io)안녕하세요. AI프렌즈 운영진 OOO입니다. ^^이번 세미나는 포항공대 OOO님을 모시고 “적대적 생성 신경망 공부 후기” 라는 내용으로 세미나를 해드립니다. GAN에 대해서는 많이 들어보셨을 텐데요. 이번 기회에 얼마나 발전하고 있는지 살펴보실 수 있는 좋은 기회가 될 것 같네요. 많은 시청 부탁 드립니다. ^^제목: 적대적 생성 신경망 공부 후기, Vanilla GAN 부터 Contra GAN까지 - 너무나도 매력적인 적대적 생성 신경망 - 천 번 넘게 학습시키면서 얻은 지식들 - 대조 학습을 이용한 조건부 이미지 생성에 대한 소개* 유튜브 링크https://www.youtube.com/watch?v=OfQq3AdRDY8"
## [2] "AI프렌즈 제60회 세미나를 안내합니다.(https://aifrenz.github.io)안녕하세요. AI프렌즈 운영진 OOO입니다. ^^이번 세미나는 포항공대 OOO님을 모시고 “적대적 생성 신경망 공부 후기” 라는 내용으로 세미나를 해드립니다. GAN에 대해서는 많이 들어보셨을 텐데요. 이번 기회에 얼마나 발전하고 있는지 살펴보실 수 있는 좋은 기회가 될 것 같네요. 많은 시청 부탁 드립니다. ^^제목: 적대적 생성 신경망 공부 후기, Vanilla GAN 부터 Contra GAN까지 - 너무나도 매력적인 적대적 생성 신경망 - 천 번 넘게 학습시키면서 얻은 지식들 - 대조 학습을 이용한 조건부 이미지 생성에 대한 소개* 유튜브 링크https://www.youtube.com/watch?v=OfQq3AdRDY8"
## [3] "톡게시판 '공지': AI프렌즈 제72회 세미나를 안내합니다.(https://aifrenz.github.io)안녕하세요. AI프렌즈 운영진 OOO입니다. ^^이번 세미나는 넥슨의 OOO님을 모시고 “강화학습 환경 개발” 이라는 내용으로 발표를 합니다. 강화학습 연구를 할 때 환경 개발이 중요한 것 아시지요? 강화학습 환경을 개발할 때 어떤 것을 고려해야 할지? 그리고, OpenAI GYM과 연동은 어떻게 할지? 생생한 내용으로 세미나를 하게 될 것 같습니다. 그럼, 많은 시청 부탁 드립니다. ^^제목: 강화학습 환경 개발- 강화학습 환경 개발을 할 때 고려할 사항- 간단한 강화학습 환경 구현해 보기- OpenAI Gym과 연동하기* 유튜브 링크https://youtu.be/PuVLgXhEBpQ"
## [4] "톡게시판 '공지': AI프렌즈 제75회 세미나를 안내합니다.(https://aifrenz.github.io)안녕하세요. AI프렌즈 운영진 OOO입니다. ^^이번 세미나는 특허법인 RPM의 신인모님을 모시고 “인공지능 연구와 비즈니스를 위한 지식재산권” 이라는 내용으로 발표를 합니다. 인공지능 관련된 특허 트렌드가 어떤지? AI기술로 지식재산권을 확보하고 싶은데 어떻게 하면 좋을지? 궁금하시죠. 그럼, 많은 시청 부탁 드립니다. ^^제목: 인공지능 연구와 비즈니스를 위한 지식재산권- 인공지능 지식재산권 관련 트렌드- AI 기술의 연구개발에 따른 지식재산권 확보방안- AI 기술 기업의 비즈니스와 지식재산권의 관계"
## [5] "AI프렌즈 제72회 세미나를 안내합니다.(https://aifrenz.github.io)안녕하세요. AI프렌즈 운영진 OOO입니다. ^^이번 세미나는 넥슨의 OOO님을 모시고 “강화학습 환경 개발” 이라는 내용으로 발표를 합니다. 강화학습 연구를 할 때 환경 개발이 중요한 것 아시지요? 강화학습 환경을 개발할 때 어떤 것을 고려해야 할지? 그리고, OpenAI GYM과 연동은 어떻게 할지? 생생한 내용으로 세미나를 하게 될 것 같습니다. 그럼, 많은 시청 부탁 드립니다. ^^제목: 강화학습 환경 개발- 강화학습 환경 개발을 할 때 고려할 사항- 간단한 강화학습 환경 구현해 보기- OpenAI Gym과 연동하기* 유튜브 링크https://youtu.be/PuVLgXhEBpQ"
findThoughts() 함수를 이용해서 대표 문서를 읽을 수 있습니다. slice() 함수를 이용해서 토픽분석에서 제외되었던 행(stm_removed)을 제거한 후 comment를 출력합니다. n은 출력할 대표문서의 개수를 가리키고 topics에 특정 토픽의 번호를 입력하면 됩니다. findThoughts() 함수 결과는 리스트 형태로 얻어지는데 그 중에서 docs에 있는 1번째가 해당 문서의 comment에 해당합니다.
대충 글을 살펴보면 중복된 내용도 있긴 하지만 토픽2는 “세미나 공지”로 토픽명을 정할 수 있을 것 같습니다.
토픽별 대표 문서 읽기2
findThoughts(stm_topics, texts=slice(data, -c(stm_removed)) %>% pull(comment), n=5, topics=3)$docs[[1]]
## [1] "환영합니다! 몇가지 안내 드려요!- 표시 이름은 소속+성함으로 표기 부탁드립니다- 24시간 자유롭게 대화가 이루어지니 알람 해제 꼭 해주세요.- 운영진 허가 없이 단순 광고글 올리시면 안되요."
## [2] "환영합니다! 몇가지 안내 드려요!- 표시 이름은 소속+성함으로 표기 부탁드립니다- 24시간 자유롭게 대화가 이루어지니 알람 해제 꼭 해주세요.- 운영진 허가 없이 단순 광고글 올리시면 안되요."
## [3] "환영합니다! 몇가지 안내 드려요!- 표시 이름은 소속+성함으로 표기 부탁드립니다- 24시간 자유롭게 대화가 이루어지니 알람 해제 꼭 해주세요.- 운영진 허가 없이 단순 광고글 올리시면 안되요."
## [4] "환영합니다! 몇가지 안내 드려요!- 표시 이름은 소속+성함으로 표기 부탁드립니다- 24시간 자유롭게 대화가 이루어지니 알람 해제 꼭 해주세요.- 운영진 허가 없이 단순 광고글 올리시면 안되요."
## [5] "환영합니다! 몇가지 안내 드려요!- 표시 이름은 소속+성함으로 표기 부탁드립니다- 24시간 자유롭게 대화가 이루어지니 알람 해제 꼭 해주세요.- 운영진 허가 없이 단순 광고글 올리시면 안되요."
토픽3는 “공지 및 안내”라고 정할 수 있을 것 같습니다. n을 20 정도로 바꾸면 비슷한 맥락의 다른 글들을 볼 수 있습니다만 관련 내용은 생략하겠습니다.
토픽별 대표 문서 읽기3
findThoughts(stm_topics, texts=slice(data, -c(stm_removed)) %>% pull(comment), n=5, topics=9)$docs[[1]]
## [1] "이 과정에서 지도교수가 충분히 디스커션이나 방향 지도 등의 형태로 기여한다면 문제가 없다고 생각합니다. 문과와 이공계가 이 부분에서 상당히 문화가 다르던데요, 문과에 있는 친구 말을 들어보니 학위논문도 논문이라 학술지에 내는 것을 중복게재로 보더군요. 그 친구 말에 따르면 \"있을 수 없는 연구 부정\"이라고까지 합니다.하지만 이공계는 학위 논문이 학위 취득을 위한 행정 서류 이상의 가치를 지니지 않는다고 생각하거든요. 앞선 연구 성과를 알기 위해 학위 논문을 찾아보지도 않구요. 연구 성과물이 나올때마다 따박따박 학회나 저널에 연구 논문으로 발표하고, 이 내용들과 연구 논문에 분량 제한 등의 이유로 실리지 않은 디테일이나 전체적인 흐름을 담아 학위논문으로 내면 문제가 없을 것 같아요"
## [2] "절대 안놔두죠. 그래서, 주위 환경이 호의적일 것이라고 결코 기대해서도 안됩니다. 계속 발목잡고, 안된다고 하고, 시기상조라고 하고, 더 협의해야 한다고 하고, 브라브라브라 ... 이런 것을 당연하게 생각하고, 상수로 놓고 전략을 짜야 합니다. 우리가 가끔 실수하는 게 생각이 옳고 뜻이 좋으니 당연히 주위 환겨이 호의적이라고 생각하는 것이죠. 그래서 놀라고, 실망도 하고 ... 세상은 그렇게 돌아가지 않는데 말이죠. "
## [3] "펀딩 전혀없이, 학위도 없는데 혼자 연구해서 ICLR 2019에 논문이 게재되어 Spotlight까지..."
## [4] "그래서 전 저희 연구원 분들한테 빅데이터라는 말부터 쓰지 말자고 해요. 예전부터 빅데이터라고 해서 가보면 열댓개인 경우도 많고 (보고만 받는 관리직 윗분은 자기네가 빅데이터 갖고있는줄 알고) 그렇다고 일 아예 못하는 것도 아니고."
## [5] "이거 깨면 억울하지 않으세요? 대학원 시절 꿈에서 신나게 디버깅하고 논문 썼는데 깨면 다 날아가는게 억울해서 밤을 새기 시작했어요."
토픽9는 “논문 연구”에 대한 내용으로 보여집니다.
토픽명이 분명하게 보이는 3개 토픽만 살펴보았습니다. 나머지는 명확하게 토픽명을 정하기 어렵네요. 그런 경우 대표 문서들 중에서도 빈도수가 높은 단어들과 그 중에서 배타적인 단어가 적절하게 들어가 있으면서 의미가 통하는 문서만 종합하여 토픽명을 정합니다. 위의 예에서와 같이 명확하게 토픽명이 보이는 경우는 흔하지 않습니다.
예고
다음 글에서 토픽들 사이의 상관관계를 시각화 해보겠습니다.
댓글남기기