카카오톡 토픽 분석4 (다양한 변수에 따른 토픽 발현확률)
미션 이해
문서(카톡글)당 토픽발현 확률을 뽑아낼 수 있습니다. 이를 이용해서 토픽별 토픽발현 확률이 높은 대표글을 시각화할 수도 있습니다. 특정 토픽을 이끌고 있는 사람이 누구인지 알 수 있죠. 특정 글쓴이의 토픽당 평균 토픽발현 확률을 뽑아낼 수도 있습니다. 이를 통해 특정 글쓴이가 어떤 토픽에 관심이 많은지 알 수 있습니다. data에 저장되어 있는 시간(hour), 오전오후(ampm) 등 다양한 변수에 따른 토픽발현 확률을 비교할 수 있습니다.
최종 결과 확인
형태소 분석하기
#### 1. 분석 준비 ####
pacman::p_load(scales, ggthemes, ggridges, # 시각화 관련 패키지
PerformanceAnalytics, pheatmap, # 상관관계 시각화
forecast, # 시계열 예측 관련 패키지
RHINO, tm, RWeka, tidytext, tidystm, # 텍스트 마이닝
igraph, ggraph, tidygraph, wordcloud2, # 텍스트 마이닝 시각화
factoextra, # 군집분석 시각화
tidymodels, textrecipes, LiblineaR, themis, # 머신러닝
lubridate, magrittr, tidyverse) # 데이터 전처리 관련 패키지
#### 2. 데이터 전처리 ####
rdata <- read_file("../data/KakaoTalkChats.txt") %>% # txt 파일 읽어오기
strsplit("\r") %>% unlist() %>% # 같은 사람의 글은 한 줄로
gsub("\n", "", .) %>% as_tibble() %>% # 줄바꿈 없애기
filter(grepl("^\\d.*,.*:", value)) %>% # 숫자시작 , : 있는 것만
separate(value, into=c("date", "text"), sep=", ", extra="merge") %>% # 날짜와 글 분리
separate(text, into=c("name", "comment"), sep=" : ", extra="merge") # 이름과 글 내용 분리
data <- rdata %>%
rownames_to_column("id") %>% # 문서 id
mutate(date=gsub("년 ", "-", gsub("월 ", "-", gsub("일 ", " ", date)))) %>%
mutate(date=gsub("오전", "AM", gsub("오후", "PM", date))) %>% # 오전 오후 구분
mutate(date=parse_date_time(date, c("%Y-%m-%d %p %H:%M"))) %>% # 날짜 형식으로
mutate(year=year(date), quarter=quarter(date), month=month(date), # 년, 분기, 월 변수 만들기
wday=weekdays(date), yday=yday(date), hour=hour(date), # 요일, 일수, 시간 변수 만들기
ampm=ifelse(hour(date)<12, "AM", "PM")) %>% # 오전 오후 변수 만들기
select(id, year:ampm, name, comment) %>% # 주요 변수 선택
mutate(형태소=comment %>% sapply(getMorph, "NV") %>% # 명사, 동사, 형용사만 선택
sapply(paste, collapse=" ")) # 형태소 분석 결과 합치기
names_top3 <- data %>% group_by(name) %>% summarise(n=n()) %>% # 발언량이 많은
arrange(desc(n)) %>% slice(1, 2, 3) %>% pull(name) # 상위 3명 이름 저장
data <- data %>%
mutate(group=as.factor(ifelse(name %in% names_top3, "Top3", "Others"))) %>% # 그룹 지정
mutate(date=ym(paste0(year, "-", month))) %>% # 년월 지정
mutate(date=as.integer(round((date-as.Date("2019-02-01"))/(365.25/12)))) # 누적 월 계산
#### 3. 구조적 토픽모델 ####
stm_pre <- textProcessor(data$형태소, data, wordLengths = c(2,Inf), customstopwords=c("사진", "이모티콘"))
stm_out <- prepDocuments(stm_pre$documents, stm_pre$vocab, stm_pre$meta, lower.thresh=3)
k <- 13
stm_topics <- stm(stm_out$documents, stm_out$vocab, K=k, prevalence=~group+s(date),
data=stm_out$meta, seed=1000, init.type="Spectral")
stm_removed <- setdiff(c(1:nrow(data)), stm_topics$mu$mu %>% as.data.frame() %>% names() %>% as.numeric())
데이터 전처리, 토픽분석 과정입니다. 이전 글에서 설명한 내용 그대로입니다.
토픽별 대표 글쓴이 보기1
tidy(stm_topics, matrix="gamma", document_names=stm_out$meta$name) %>% # gamma와 이름 뽑아내기
mutate(topic=paste0("Topic ", topic), document=as.factor(document)) %>% # "topic" 추가
mutate(topic=fct_reorder(topic, parse_number(topic))) %>% # 숫자순으로 factor 처리
group_by(topic) %>% slice_max(gamma, n=10) %>% droplevels() %>% ungroup() %>% # 토픽당 10개 문서 선택
ggplot(aes(x=gamma, y=reorder_within(document, gamma, topic), fill=topic)) +
geom_col(show.legend = FALSE) +
theme_bw() +
facet_wrap(vars(topic), scales = "free_y") +
scale_y_reordered() +
labs(x = NULL, y = expression(gamma), title = "토픽별 대표 글쓴이 보기")

토픽별 토픽발현확률(gamma)가 큰 문서 10개를 선정해서 토픽별 발현확률을 그래프로 나타냅니다.
tidy() 함수로 gamma값을 꺼내기 위해서는 matrix를 “gamma”로 지정해야 합니다. document_names를 stm_outmet**aname로 지정하면 name, topic, gamma를 끄집어 낼 수 있습니다. fct_reorder() 함수는 문자로 되어 있는 변수를 factor로 바꿀 수 있고 문자와 숫자가 붙어 있을 때 숫자순으로 factor levels를 지정할 수 있습니다. 이 함수를 적용하지 않으면 1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9 순으로 그래프가 그려집니다. fct_reorder() 함수를 지정해야 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 순으로 정렬됩니다.
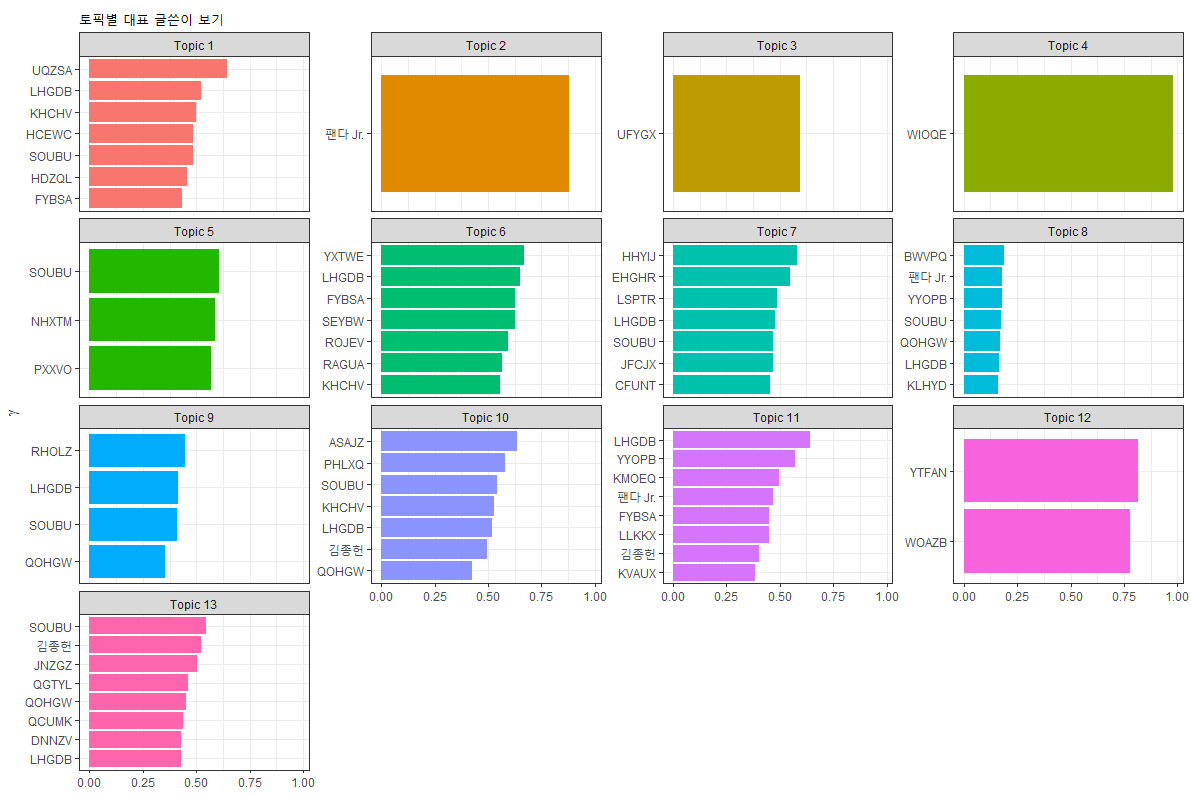
그래프로 시각화하는 것은 이전 글에서 설명한 코드 그대로 입니다. 팬다 Jr.과 제 이름(김종헌)만 그대로 남겨두고 나머지 글쓴이는 무작위 알파벳으로 바꿔 표현했습니다.
Topic 2는 “공지 및 안내”인데 팬다 Jr.라는 카카오톡 챗봇이 그 역할을 했다는 것을 알 수 있습니다. 상위 10개 문서가 모두 팬다 Jr. 문서이기 때문에 팬다 Jr.만 그래프에 표현되었습니다. 아울러 10개 문서의 gamma값을 모두 합해서 그래프에 표현되었기 때문에 x축의 값이 1보다 큽니다. reorder_within() 함수로 토픽별로 감마값이 큰 것에서부터 작은 것 순으로 정렬했음에도 불구하고 정렬이 안 된 모습을 볼 수 있습니다. 그 이유도 상위 10개 문서 중에 같은 사람의 문서가 2개 이상 중복되면서 누적되었기 때문에 크기순으로 정렬되지 않은 것을 볼 수 있습니다. 해당 토픽발현 확률이 가장 큰 사람은 누구인지 알 수 있다는 장점과 함께 누가 해당 토픽을 주도하고 있는지를 알 수 있기 때문에 나름대로 의미있는 시각화입니다.
그럼 같은 사람의 문서가 여러 개 있을 때 토픽발현확률의 평균값으로 시각화하려면 어떻게 해야할까요?
토픽별 대표 글쓴이 보기2
tidy(stm_topics, matrix="gamma", document_names=stm_out$meta$name) %>% # gamma와 이름 뽑아내기
mutate(topic=paste0("Topic ", topic), document=as.factor(document)) %>% # "topic" 추가
mutate(topic=fct_reorder(topic, parse_number(topic))) %>% # 숫자순으로 factor 처리
group_by(topic) %>% slice_max(gamma, n=10) %>% droplevels() %>% ungroup() %>% # 토픽당 10개 문서 선택
group_by(document, topic) %>% summarise(gamma=mean(gamma)) %>% # 문서, 토픽당 평균
ggplot(aes(x=gamma, y=reorder_within(document, gamma, topic), fill=topic)) +
geom_col(show.legend = FALSE) +
theme_bw() +
facet_wrap(vars(topic), scales = "free_y") +
scale_y_reordered() +
labs(x = NULL, y = expression(gamma), title = "토픽별 대표 글쓴이 보기")
발언자(document)와 토픽(topic) 별로 gamma의 평균값을 구해서 시각화하면 됩니다. x축의 최댓값이 1인 것을 확인할 수 있습니다. topic 8의 경우 서브 주제인 것 같네요.
토픽별로 10명씩 모두 다 포함시키고 싶다면 어떻게 해야할까요?
토픽별 대표 글쓴이 보기3
tidy(stm_topics, matrix="gamma", document_names=stm_out$meta$name) %>%
mutate(topic=paste0("Topic ", topic), document=as.factor(document)) %>%
mutate(topic=fct_reorder(topic, parse_number(topic))) %>%
group_by(topic) %>% slice_max(gamma, n=150) %>% # 넉넉하게 문서 선택
filter(!duplicated(document)) %>% # 발언자가 중복되면 제거
slice_max(gamma, n=10) %>% # 상위 10개만 남기기
droplevels() %>% ungroup() %>% # factor levels 제거
ggplot(aes(x=gamma, y=reorder_within(document, gamma, topic), fill=topic)) +
geom_col(show.legend = FALSE) +
theme_bw() +
facet_wrap(vars(topic), scales = "free_y") +
scale_y_reordered() +
labs(x = NULL, y = expression(gamma), title = "토픽별 대표 글쓴이 보기")

slice_max() 함수로 넉넉하게(여기선 150개 이상) 선택한 후 duplicated() 함수로 중복된 것을 찾아 제거합니다. 이 때 slice_max() 함수를 썼기 때문에 자동으로 gamma값이 내림차순으로 정렬되기 때문에 gamma가 가장 큰 것만 남고 나머지가 모두 제거됩니다. 그 후에 slice_max() 함수를 써서 상위 10개만 남깁니다. 이하 시각화는 동일합니다.
Top3의 평균 토픽발현 확률
tidy(stm_topics, matrix="gamma") %>%
merge(select(slice(data, -stm_removed), name) %>% rownames_to_column("document")) %>%
group_by(name, topic) %>% summarise(gamma=mean(gamma)) %>%
filter(name %in% names_top3) %>%
mutate(name=as.factor(name)) %>%
ggplot(aes(y=gamma, x=as.factor(topic), fill=as.factor(topic))) +
geom_bar(stat="identity",alpha = 0.8, show.legend = FALSE) +
theme_bw() +
facet_wrap(~name, ncol=1) +
labs(subtitle="Top3에 대한 토픽별 평균 발현 확률", y=expression(gamma), x="Topic")
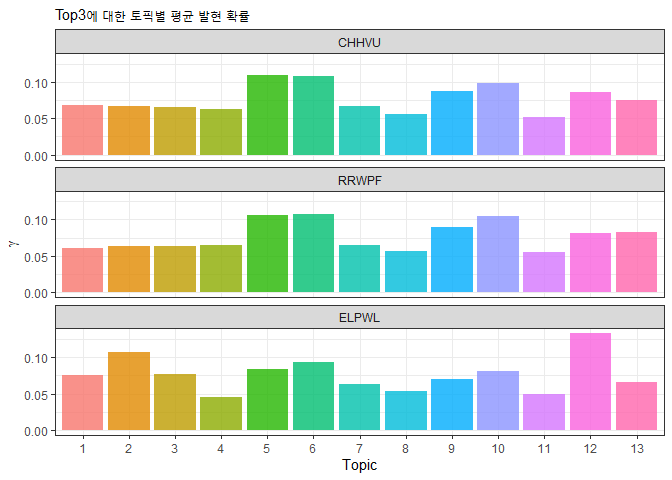
tidy() 함수의 document_names 파라미터를 이용해서 글쓴이의 정보까지 뽑아낼 수 있습니다. 하지만 다른 방법으로 글쓴이를 알아낼 수도 있습니다. slice() 함수를 써서 stm_removed 행을 제거하고 name 변수를 선택(select)한 후 merge() 함수를 써서 데이터를 합치는 방법이 있습니다. 이 방법을 사용하면 name 뿐만 아니라 내가 원하는 변수를 한꺼번에 여러개도 소환할 수 있습니다. merge() 함수를 쓰기 위해서는 공통된 변수가 있어야 하는데 document 변수를 만들기 위해 행번호를 rownames_to_column() 함수로 끄집어 내서 document 변수로 만들어 줍니다. 그리고 merge() 함수를 쓰면 document, topic, gamma로 된 문서와 document, name으로 된 문서가 document를 기준으로 적절하게 잘 합쳐집니다.
발언이 많은 사람은 토픽5, 토픽6, 토픽10, 토픽9, 토픽12 등에 관심이 상대적으로 높은 것을 알 수 있습니다.
오전, 오후의 평균 토픽 발현 확률
tidy(stm_topics, matrix="gamma") %>% arrange(document, topic) %>%
merge(select(slice(data, -stm_removed), ampm) %>% rownames_to_column("document")) %>%
group_by(ampm, topic) %>% summarise(gamma=mean(gamma)) %>%
ggplot(aes(y=gamma, x=as.factor(topic), fill=as.factor(topic))) +
geom_bar(stat="identity",alpha = 0.8, show.legend = FALSE) +
theme_bw() +
facet_wrap(~ampm, ncol=1) +
labs(subtitle="오전과 오후의 평균 토픽 발현 확률", y=expression(gamma), x="Topic")
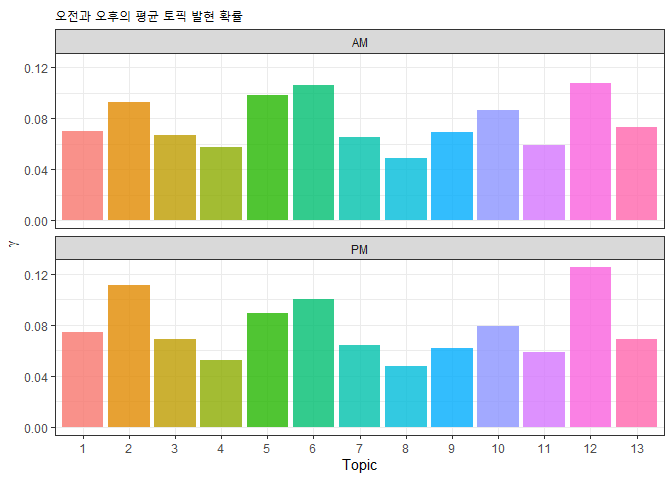
topicCorr() 함수로 토픽간 상관관계를 구하는데 cutoff를 0.1로 설정하여 상관계수가 0.1이 안 되는 경우 토픽간 단절시키는 방식으로 시각화 하였습니다. 계층적 군집분석에 의한 군집을 색으로 표현하였습니다.
시간(hour)에 따른 평균 토픽 발현 확률
tidy(stm_topics, matrix="gamma") %>% arrange(document, topic) %>%
merge(slice(data, -stm_removed) %>% select(hour) %>% rownames_to_column("document")) %>%
group_by(hour, topic) %>% summarise(gamma=mean(gamma)) %>%
mutate(topic=as.factor(topic)) %>%
filter(topic %in% c(2, 9)) %>%
ggplot(aes(x=hour, y=gamma, color=topic)) +
geom_point() + geom_line() + theme_bw() +
theme(legend.position = c(0.32, 0.8)) +
labs(subtitle="시간(hour)에 따른 평균 토픽 발현 확률", y=expression(gamma), x="Topic")
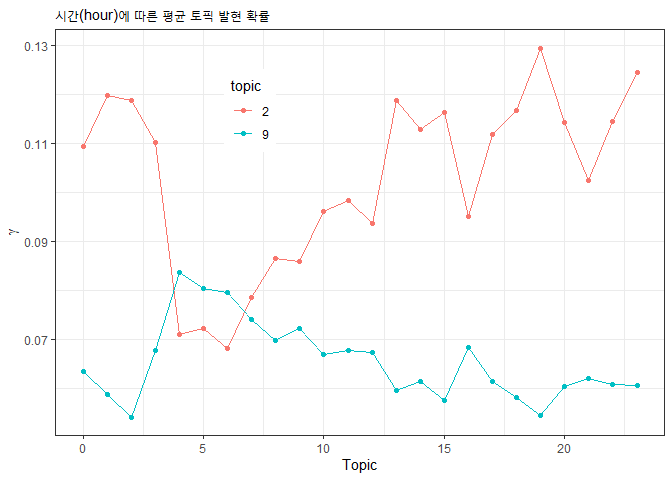
merge() 함수를 적용할 때 적절한 변수만 선택해주면 그 변수에 따른 토픽발현 확률을 비교할 수 있습니다. 13개 토픽을 모두 표현하면 너무 산만하기 때문에 토픽2와 토픽9만 선택했습니다. filter(topic %in% c(2, 9))는 topic에 2나 9가 있는 문서만 선택한다는 뜻입니다.
월(month)에 따른 평균 토픽 발현 확률
tidy(stm_topics, matrix="gamma") %>% arrange(document, topic) %>%
merge(slice(data, -stm_removed) %>% select(month) %>% rownames_to_column("document")) %>%
group_by(month, topic) %>% summarise(gamma=mean(gamma)) %>%
mutate(topic=as.factor(topic)) %>%
filter(topic %in% c(2, 9)) %>%
ggplot(aes(x=month, y=gamma, color=topic)) +
geom_point() + geom_line() + theme_bw() +
theme(legend.position = c(0.85, 0.85)) +
labs(subtitle="월(month)에 따른 평균 토픽 발현 확률", y=expression(gamma), x="Topic")
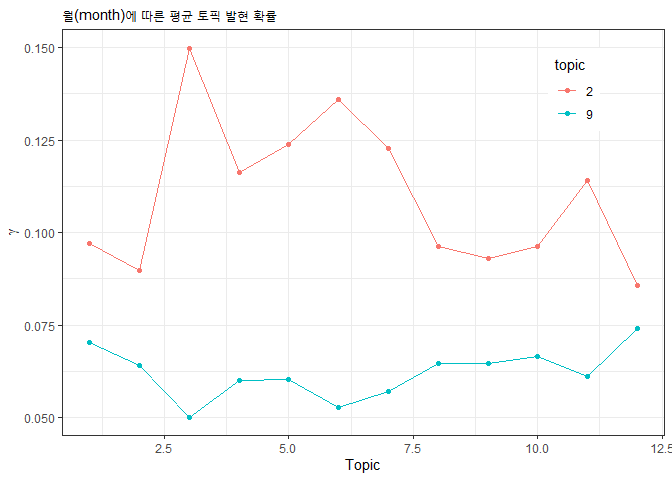
merge() 함수를 적용할 때 적절한 변수만 month를 선택해서 월별 평균 토픽 발현 확률을 비교해 보았습니다.
예고
다음 글에서 토픽발현 확률을 종속변수로 선택하고 다른 변수들을 독립변수로 선정하여 회귀분석을 실시하도록 하겠습니다.
댓글남기기