카카오톡 글 쓴이 예측 머신러닝
미션 이해
다들 비슷한 주제로 비슷한 말들을 하면 글 쓴이를 구별하기 힘듭니다. 특정 단어나 특정 주제에 집중하는 사람의 대화를 선택하면 단어를 이용해서 글 쓴이를 특정지을 수 있습니다. 데이터가 많아야 하기 때문에 대화량이 많은 사람들 중에서 3명을 선택하는 것이 좋습니다. LiblineaR 패키지에서 지원하는 서포트 벡터 머신 알고리즘을 사용하면 어떤 단어로 글 쓴이를 특정짓는지 알아낼 수 있습니다.
최종 결과 확인
시계열 데이터 만들기
pacman::p_load(ggthemes, # 시각화 관련 패키지
RHINO, # 텍스트 마이닝(형태소 분석)
tidymodels, textrecipes, LiblineaR, # 머신러닝
lubridate, tidyverse) # 데이터 전처리 관련 패키지
initRhino()
rdata <- read_file("KakaoTalkChats.txt") %>% # txt 파일 읽어오기
strsplit("\r") %>% unlist() %>% # 같은 사람의 글은 한 줄로
gsub("\n", "", .) %>% as_tibble() %>% # 줄바꿈 없애기
filter(grepl("^\\d.*,.*:", value)) %>% # 숫자시작 , : 있는 것만
separate(value, into=c("date", "text"), sep=", ", extra="merge") %>% # 날짜와 글 분리
separate(text, into=c("name", "comment"), sep=" : ", extra="merge") # 이름과 글 내용 분리
data <- rdata %>%
mutate(date=gsub("년 ", "-", gsub("월 ", "-", gsub("일 ", " ", date)))) %>%
mutate(date=gsub("오전", "AM", gsub("오후", "PM", date))) %>%
mutate(date=parse_date_time(date, c("%Y-%m-%d %p %H:%M"))) %>% # 날짜 형식으로
mutate(year=year(date), quarter=quarter(date), month=month(date), # 년, 분기, 월 변수 만들기
wday=weekdays(date), yday=yday(date), hour=hour(date), # 요일, 일수, 시간 변수 만들기
ampm=ifelse(hour(date)<12, "AM", "PM")) %>% # 오전 오후 변수 만들기
select(year:ampm, name, comment)
three <- data %>% group_by(name) %>% summarise(n=n()) %>% # 이름별 대화량
arrange(desc(n)) %>% slice(1, 4, 6) %>% pull(name) # 1, 4, 6 순위 이름 뽑아내기
ml_data <- data %>% filter(name %in% three) %>% # 3명의 대화만 선택
mutate(형태소=comment %>% sapply(getMorph, "NV") %>% # RHINO 패키지로 형태소 분석
sapply(paste, collapse=" ")) %>% # 형태소들 묶기
mutate(형태소=형태소 %>% # 1음절 단어 삭제를 위해
sapply(str_extract_all, "[가-힣]{2,}") %>% # 2음절 이상만 선택
sapply(paste, collapse=" ")) %>% # 형태소들 묶기
filter(nchar(형태소)>2) %>% # 2음절 단어가 1개 뿐이면 삭제
mutate(name=as.factor(name)) %>% droplevels() # factor 레벨 정리
rdata는 전처리가 거의 없는 데이터이고 data는 EDA나 머신러닝, 텍스트 마이닝 등에 사용될 범용적인 데이터입니다. 그리고 ml_data는 머신러닝만을 목적으로 만든 1회성 데이터입니다.
name %in% three 는 three(3명의 이름)에 포함된 name만 선택한다는 표현입니다.
“사과가”, “사과를” 와 같이 같은 사과인데 조사가 붙어서 다른 단어로 취급될 수 있습니다. 같은 의미의 단어임을 확인하기 위해 형태소 분석을 실시해야 합니다. KoNLP가 매우 섬세하게 분석할 수 있기 때문에 더 유명하지만 사용하기가 너무 불편합니다. PHINO 패키지는 띄어쓰기가 안 된 문장까자 알아서 띄어쓰기를 해주고 java의 도움을 받기 때문에 시간도 매우 짧아서 사용하기 너무 편합니다. initRhino() 함수는 RHINO 패키지에서 java와 연결해서 형태소 분석을 위한 준비에 해당됩니다.
RHINO 패키지를 설치하기 위해서는 Rstudio를 실행하기 전에 Java, Rtools를 설치해야 합니다. Rstudio에서 rJava도 설치해 주어야 합니다. 아울러 RHINO는 github에서 설치해 주어야 합니다. devtools 패키지를 설치한 후 devtools::install_github(“SukJaeChoi/RHINO”, force=T) 로 설치할 수 있습니다.
개인적으로 다른 작업을 할 때 KoNLP, RcppMeCab, RHINO 3개의 형태소 분석기를 사용해봤습니다. 형태소 분석 후 이어 붙이는 작업을 비교해보면 KoNLP가 46.25초, RcppMeCab가 34.15초, RHINO가 2.22초로 RHINO가 가장 빨랐습니다. 형태소 분석한 결과를 비교해 봐도 RHINO가 가장 많은 단어들을 뽑아내더군요. 그 이후로 형태소 분석은 RHINO만 사용합니다.
str_extract_all() 함수는 특정 조건에 맞는 글자만 선택하는데 사용합니다. [가-힣]{2,}는 2음절 이상을 의미합니다. 2~5음절만 선택하고 싶다면 [가-힣]{2,5}로 지정하면 됩니다.
데이터 나누기
ml_splits <- initial_split(ml_data, 0.9, strata=name)
train과 test 데이터로 나누기 위한 정보를 만듭니다. training() 함수를 사용해서 train 데이터를 만들고 testing() 함수를 이용해서 test 데이터를 만드는 것이 일반적이지만 1회만 사용할 거라 굳이 train 데이터와 test 데이터를 만들지 않았습니다.
모델 만들고 평가하기
collect_metrics(
ml_fitted <-
last_fit(
workflow(recipe(name ~ 형태소, data = training(ml_splits)) %>%
step_tokenize(형태소) %>%
step_tokenfilter(형태소, max_tokens = 20) %>%
step_tfidf(형태소),
svm_linear() %>%
set_mode("classification") %>%
set_engine("LiblineaR")
),
ml_splits,
metrics = metric_set(accuracy, precision, recall)
)
)
## # A tibble: 3 x 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 accuracy multiclass 0.711 Preprocessor1_Model1
## 2 precision macro 0.810 Preprocessor1_Model1
## 3 recall macro 0.502 Preprocessor1_Model1
정확도는 71.1%입니다. 데이터가 수천개로 train과 test 데이터가 어떻게 나눠지느냐에 따라 조금씩 달라질 수 있습니다. macro recall이 그닥 높지 않은 것으로보아 쓸만한 정도는 아니네요. 그냥 재미삼아 분석하는 것으로 이해해 주세요. ^^
일반적으로는 여러 머신러닝 알고리즘을 비교해서 평가지표가 좋은 알고리즘을 선택하는 것이 일반적입니다. 하지만 다른 일반적인 알고리즘의 경우 왜 그런 결과가 나왔는지를 제대로 알려주지 않습니다. 통계 알고리즘을 사용하면 어떤 단어가 글 쓴이를 특정 짓는데 어느 정도 기여하는지를 알 수 있지만 정확도가 떨어진다는 문제점이 있습니다. 다행히 LiblineaR 패키지는 정확도도 높으면서 회귀계수도 출력해주기 때문에 바로 이 알고리즘으로 분석하였습니다.
최종 적용이라 last_fit() 함수를 적용하였고 workflow() 함수를 이용하여 레시피(recipe)와 머신러닝 알고리즘을 설정하였습니다. ml_splits를 통해 test 데이터에 적용해서 평가 지표를 뽑아냅니다. metrics 파라미터로 정확도(accuracy), 정밀도(precision), 재현율(recall)를 지정하였습니다.
레시피는 형태소 분석한 글을 토큰화하고 상위 20개 단어만 선택하도록 하였습니다. 글 쓴이를 구별하는 것이 목표이므로 tfidf를 뽑아냈습니다.
svm_linear() 모델을 적용하였으며 분류(classification)이고 LiblineaR 엔진을 선택해 주었습니다.
글 쓴이를 특정짓는 단어들
extract_workflow(ml_fitted)[[2]][[2]][[3]][[3]] %>% data.frame() %>%
rename_all(~str_remove(., "tfidf_형태소_")) %>%
slice(1) %>% t() %>% data.frame() %>% rownames_to_column("term") %>%
rename(estimate=2) %>% filter(term!="Bias") %>%
ggplot(aes(estimate, fct_reorder(term, estimate), fill = estimate > 0)) +
geom_col(alpha = 0.8, show.legend=F) +
theme_few() +
labs(y="", title="AAA님을 특징 짓는 단어들")

extract_workflow(ml_fitted)[[2]][[2]][[3]][[3]] %>% data.frame() %>%
rename_all(~str_remove(., "tfidf_형태소_")) %>%
slice(2) %>% t() %>% data.frame() %>% rownames_to_column("term") %>%
rename(estimate=2) %>% filter(term!="Bias") %>%
ggplot(aes(estimate, fct_reorder(term, estimate), fill = estimate > 0)) +
geom_col(alpha = 0.8, show.legend=F) +
theme_few() +
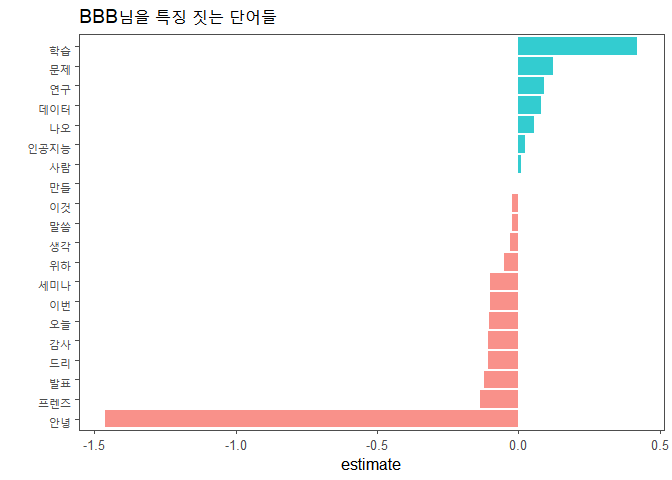
labs(y="", title="BBB님을 특징 짓는 단어들")
extract_workflow(ml_fitted)[[2]][[2]][[3]][[3]] %>% data.frame() %>%
rename_all(~str_remove(., "tfidf_형태소_")) %>%
slice(3) %>% t() %>% data.frame() %>% rownames_to_column("term") %>%
rename(estimate=2) %>% filter(term!="Bias") %>%
ggplot(aes(estimate, fct_reorder(term, estimate), fill = estimate > 0)) +
geom_col(alpha = 0.8, show.legend=F) +
theme_few() +
labs(y="", title="CCC님을 특징 짓는 단어들")
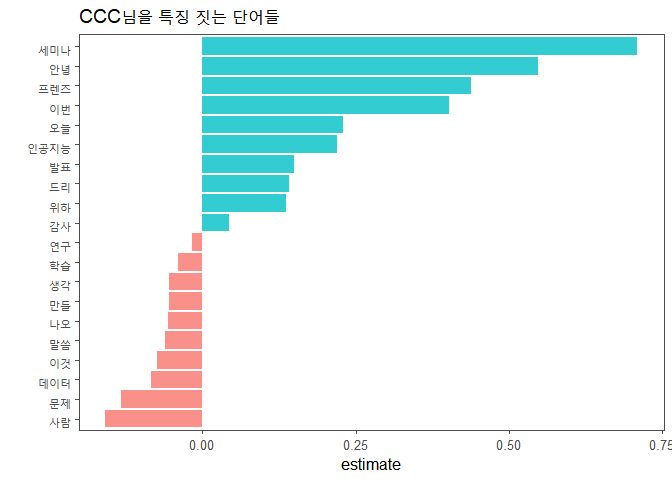
세 사람의 글을 구별하는데 사용된 단어들입니다. 상대적으로 특정 단어를 많이 언급하면 estimate가 양수로 큰 값을 가리키고 상대적으로 언급한 횟수가 적으면 음수로 큰 값을 가리키게 됩니다.
extract_workflow(ml_fitted)에 지저분하게 2와 3의 숫자를 많이 붙였습니다. list 형태로 데이터가 출력되기 때문에 로우 데이터에 접근하려다보니 이렇게 됐습니다. 각 단어별로 세 사람에 대한 estimate가 잘 정리된 데이터에 접근해서 레시피 적용 과정에서 붙은 “tfidf_형태소_”를 삭제합니다. slice(1), slice(2), slice(3)는 각각 첫 번째부터 세 번째까지의 사람을 가리킵니다. extract_workflow(ml_fitted)[[2]][[2]][[3]][[3]]만 블록을 지정해서 실행시키면 첫 번째부터 세 번째까지의 사람이 누구인지 알 수 있습니다. 시각화하기 편한 데이터 형태로 바꾸고 “Bias”라는 단어는 삭제합니다.
시각화할 때 estimate의 값을 기준으로 0보다 큰지의 여부를 fill 파라미터에 입력해서 두 그룹으로 만들고 색을 지정합니다.
예고
다음 글에서는 단어 빈도수, 단어간 상관관계 등을 분석해 보도록 하겠습니다.
댓글남기기