카카오톡 대화 EDA(3)
미션 이해
예를 들어 시간에 따른 발언량의 경우 선 그래프는 절대적인 값을 기준으로 그래프를 그립니다. 범주별로 비교할 때 그 값이 1000과 100으로 다르다고 할 때 절대적인 값의 차이가 그래프로 나타납니다. 이 경우 100의 경우 상대적으로 매우 작아서 변화량이 눈에 잘 띄지 않습니다. 하지만 확률밀도함수의 경우 발언수가 1000개이든 100개이든 똑같이 확률 1이 되기 때문에 변화량을 동일한 스케일로 확인할 수 있습니다. 장단점이 분명하기 때문에 목적에 맞게 잘 사용하는 것이 중요합니다.
최종 결과 확인
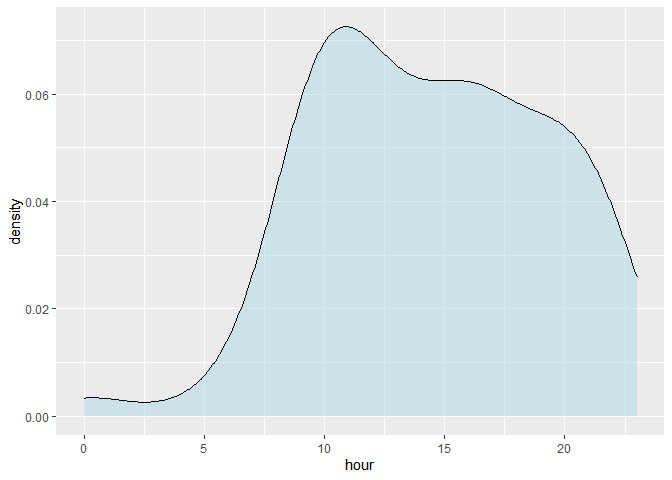
시간(hour)에 따른 발언수
pacman::p_load(scales, ggthemes, ggridges, # 시각화 관련 패키지
tidyverse, lubridate) # 데이터 전처리 관련 패키지
data %>% ggplot(aes(x=hour)) + geom_density(adjust=3, fill="lightblue", alpha=0.5)
년도별 시간에 따른 발언수
data %>% ggplot(aes(x=hour, fill=factor(year))) +
geom_density(adjust=3, alpha=0.3) +
scale_x_continuous(breaks=seq(1, 24, 3)) +
theme_few() +
theme(legend.position = c(0.15, 0.8)) +
labs(x = "시간", y = "density", title = "년도별 시간에 따른 대화 밀도 비교", fill="year")
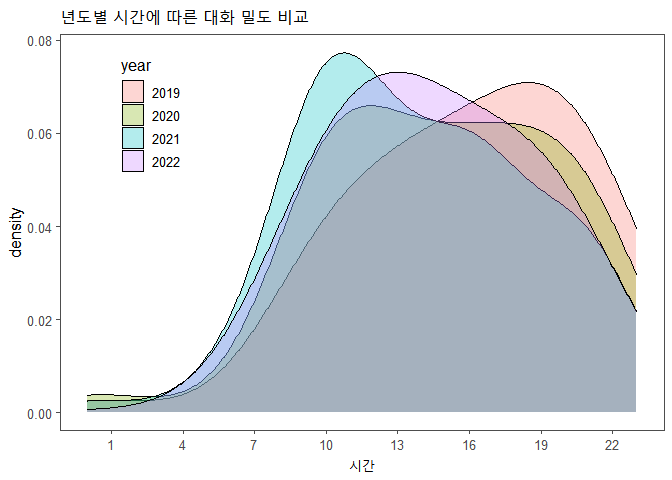
2019년도의 경우 데이터 수가 많지 않아서 절대적인 양이 2020년이나 2021년에 비해 작은 편에 속합니다. 2022년은 더 심해서 몇 일 안 되기 때문에 선 그래프로 분석할 때는 2019년, 2022년 데이터는 제외하고 분석했어야 했습니다. 하지만 확률밀도함수로 그린다면 큰 문제없이 서로 비교할 수 있습니다.
요일별 시간에 따른 발언수1
data %>% ggplot(aes(x=hour, fill=wday)) + geom_density(adjust=3, alpha=0.3)
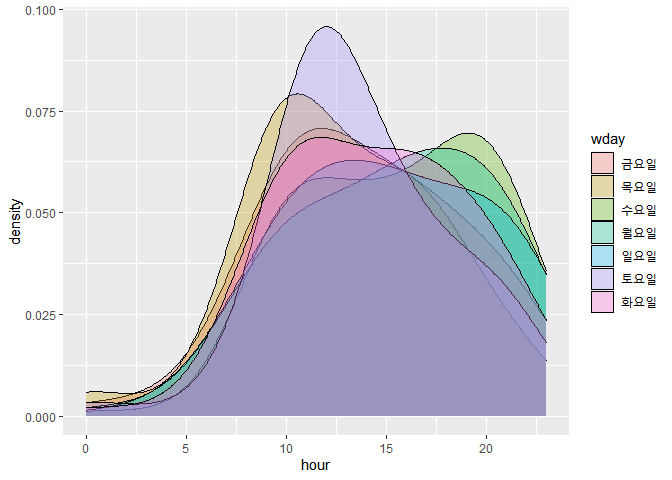
요일이 너무 많다보니 제대로 비교가 안되는 문제가 있습니다. ggridges 패키지를 이용해서 요일을 분리해서 보면 한결 보기 편합니다. 그 결과는 다음과 같습니다.
요일별 시간에 따른 발언수2
data %>%
# mutate(wday=factor(wday, levels=c("일요일","토요일","금요일","목요일","수요일","화요일","월요일"))) %>%
mutate(wday=factor(wday, levels=c("Sunday","Saturday","Friday","Thursday","Wednesday","Tuesday","Monday"))) %>%
ggplot(aes(x=hour, y=wday, fill=wday)) +
geom_density_ridges(show.legend=F, bandwidth=1) + # 확률밀도함수 그래프를 펼치기
theme_ridges() + # 그래프 테마 적용
scale_fill_brewer(palette = "Pastel2") +
labs(x="시간", y="", title="시간대별 대화량")
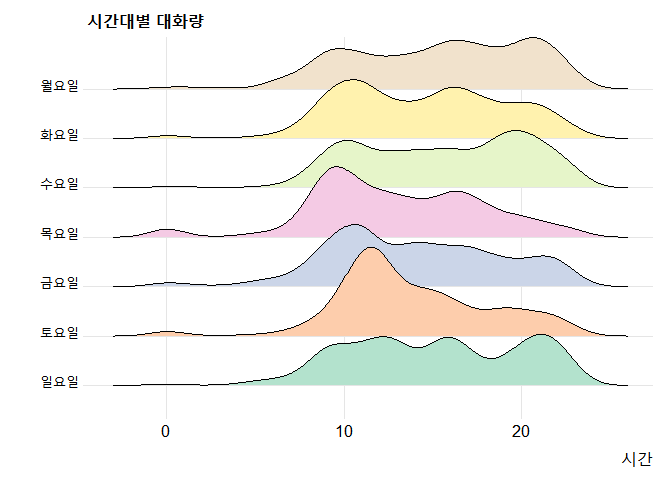
요일이 영문으로 표시되는 경우의 코드가 위와 같고 요일이 한글일 경우 한글 요일에 해당하는 코드의 주석(#)을 없애주고 영어로 된 요일과 관련된 코드에 주석처리를 해주어야 합니다.
코드 설명
확률밀도 함수 그리기
확률밀도함수 그래프의 경우 x축의 변수만 지정합니다. aes(x=hour)의 경우 hour 변수를 x축으로 놓고 전체 대화량을 1로 놓고 각 시간대별 상대적인 대화량을 그래프로 나타내줍니다. geom_density() 함수에서 adjust값에 따라 뾰족 뾰족하게, 혹은 완만하게 보여지게 만들 수 있습니다. 숫자가 작을수록 값의 변동이 명확하게 나타나고 값이 클수록 완만하게 보여줍니다.
축의 눈금 간격 조정
scale_x_continuous() 함수에서 breaks 파라미터를 통해 x축의 눈금 간격을 조정할 수 있습니다. seq(1, 24, 3)는 1에서 24까지의 값을 3의 간격으로 눈금을 만들라는 뜻이 된다.
ggridges
ggridges 패키지에서 지원하는 geom_density_ridges() 함수는 범주별 확률밀도함수 그래프를 펼쳐서 보여주는 기능을 합니다. theme_ridges() 테마를 통해 배경을 없애줌으로써 선명하게 보이게 만들어 줄 수 있습니다. scale_fill_brewer() 함수를 이용해서 palette를 Pastel2로 지정해서 색을 부드럽게 만들면 한결 보기 좋아집니다.
예고
다음 글에서는 월별 대화량이라는 시계열 데이터를 바탕으로 카톡방 대화를 다운 받은 시점 이후의 발언량을 예측해 보도록 하겠습니다.
댓글남기기