카카오톡 대화 EDA(2)
미션 이해
분석이 많아지고 다양해지다보면 그에 따른 패키지가 많아집니다. 여러 줄에 걸쳐서 작성할 수도 있지만 코드 작성하기도 불편하고 관리도 쉽지 않습니다. 어떻게 하면 쉽게 표현하고 관려할 수 있는지 살펴볼께요.
시간이나 날짜처럼 연속된 변수에 따른 발언 수는 선 그래프로 그리는 것이 좋습니다. 선 그래프는 어떻게 표현하는지 살펴봅시다.
최종 결과 확인
시간에 따른 발언수
pacman::p_load(scales, ggthemes, # 시각화 관련 패키지
tidyverse, lubridate) # 데이터 전처리 관련 패키지
data %>% group_by(hour) %>% summarise(n=n()) %>%
ggplot(aes(hour, n)) +
geom_point() + geom_line() +
geom_smooth(formula=y~x, method=loess) +
scale_y_continuous(label=comma) +
theme_few() +
labs(x = "시간", y = "발언수", title = "시간에 따른 대화량 비교")
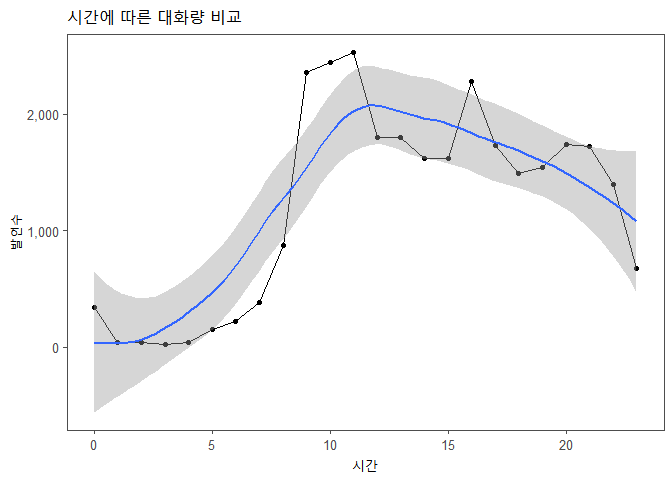
년도별 시간에 따른 발언수
data %>% filter(year %in% 2020:2021) %>%
mutate(year=factor(year)) %>%
group_by(year, hour) %>% summarise(n=n()) %>%
ggplot(aes(hour, n, color=year)) +
geom_point() + geom_line() +
geom_smooth(aes(group=year, fill=year), formula=y~x, method=loess, alpha=0.2) +
scale_y_continuous(label=comma) +
theme_few() +
labs(x = "시간", y = "발언수", title = "년도별 시간에 따른 대화량 비교")
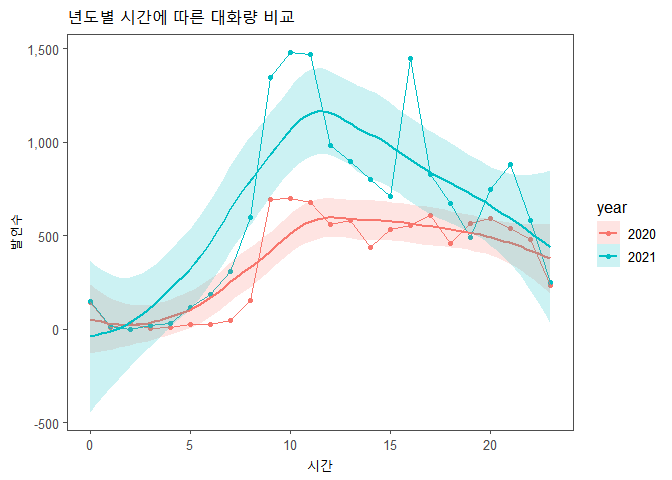
년도별 월에 따른 발언수
data %>% filter(year %in% 2020:2021) %>%
group_by(year, month) %>% summarise(n=n()) %>%
mutate(year=factor(year)) %>%
ggplot(aes(month, n, color=year)) +
geom_point() + geom_line() +
geom_smooth(aes(group=year, fill=year), formula=y~x, method=loess, alpha=0.2) +
scale_y_continuous(label=comma) +
scale_x_continuous(breaks=seq(1, 12, 1)) +
theme_few() +
theme(legend.position = c(0.2, 0.8)) +
labs(x = "월", y = "발언수", title = "년도별 월에 따른 대화량 비교")
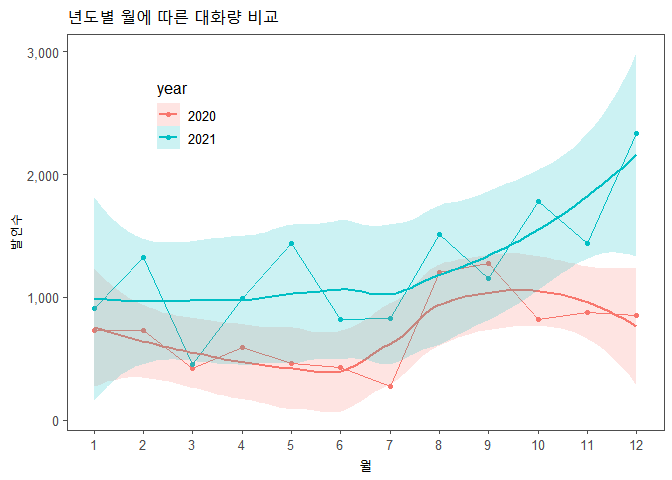
연속된 월에 따른 발언수
data %>% filter(year %in% 2020:2021) %>%
group_by(year, month) %>% summarise(n=n()) %>%
mutate(date=ym(paste0(year, "-", month))) %>%
ggplot(aes(date, n)) +
geom_point() + geom_line() +
geom_smooth(formula=y~x, method=loess, alpha=0.2) +
scale_y_continuous(label=comma) +
theme_few() +
labs(x = "년 월", y = "발언수", title = "연속된 월에 따른 대화량 비교")
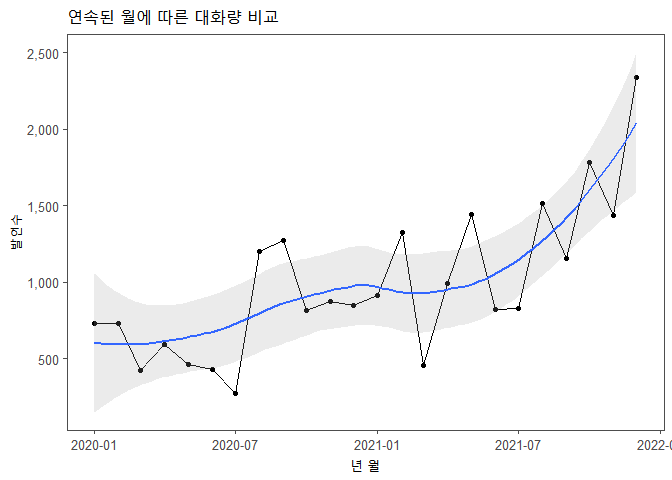
코드 설명
패키지 관리
여러 개의 패키지를 실행시킬 경우 library() 함수를 반복적으로 사용해야 합니다. 이를 반복하지 않고 한꺼번에 불러올 수 있도록 도와주는 패키지가 있습니다. pacman이라는 패키지인데 p_load() 함수를 통해 관련 패키지가 없는 경우 자동으로 설치해주는 기능까지 있어서 매우 유용합니다. p_load() 함수를 사용하기 위해서는 library(pacman)을 실행시켜 주어야 합니다. 그런데 이 부분도 불편할 수 있습니다. 그 경우 pacman::p_load() 와 같이 함수 앞에 패키지 이름과 콜론 2개를 붙여주면 library() 함수를 사용하지 않고 1회용으로 해당 패키지에서 제공하는 함수를 사용할 수 있습니다. 그리고 시각화를 위한 패키지나 데이터 전처리 과정에서 필요한 패키지 등으로 구분해서 표시하면 실행과 관리 모든 측면에서 매우 유용합니다.
년도와 월별 빈도수 통계내기
group_by() 함수에 year, month 두 변수를 입력하면 년도와 월을 구분해서 통계를 낼 수 있습니다.
년도와 월로 date 만들기
lubridate 패키지에서 제공하는 ym() 함수를 이용하면 년도와 월을 “-”로 묶어준 문자를 날짜로 바꿀 수 있습니다. paste0() 함수는 띄어쓰기 없이 데이터와 문자 등을 붙여줍니다.
선 그래프 그리기
geom_point() 함수는 점을 찍어줍니다. geom_line() 함수는 선을 그어줍니다. 보통은 두 가지 모두 실행시켜주어야 보기 좋아집니다.
geom_smooth() 함수는 데이터의 경향성을 시각화해줍니다. method 파라미터에 “lm”을 입력하면 선형으로 추세선을 그려주고, “loess”를 입력하면 곡선으로 된 경향성을 시각화 해줍니다. method가 lm인 경우 formula 파라미터를 이용해서 y절편의 값이 0이 아닌 추세선 혹은 y절편이 0인 추세선을 그릴 수 있습니다. formula에 “y~x”로 입력하면 y절편이 0이 아닐 수 있습니다. 하지만 formula 파라미터에 “y~0+x”를 입력하면 강제로 y절편을 0으로 맞춰서 추세선을 그려줍니다. alpha는 투명한 정도를 나타냅니다. aes()로 그래프의 축과 함께 group을 통해 범주별로 구분하여 경향성을 표현할 수 있습니다. aes() 속 fill은 색을 구별해서 표현해 줄 변수를 입력하면 범주별 연속형 변수에 따른 연속병 변수의 값을 시각화할 수 있습니다.
scale_x_continuous() 함수에 label 파라미터를 이용해서 1000 단위로 콤마를 붙일 수도 있지만 breaks 파라미터를 이용해서 축의 값 범위와 간격을 조정할 수 있습니다.
범례 위치 조정
theme() 함수 속 legend.position 파라미터를 이용해서 위치를 조정할 수 있습니다. 그래프의 가로와 세로가 각각 1에 해당하기 때문에 0.2, 0.8이면 왼쪽에서 20% 오른쪽, 위쪽으로 80% 위치에 범례를 표시한다는 의미입니다.
예고
다음 글에서는 밀도함수를 통해 더 깊이 있게 분석해 보겠습니다.
댓글남기기