카카오톡 대화 EDA(1)
미션 이해
년도, 월, 일, 요일, 오전 오후, 시간 등 데이터 분석에 필요한 각종 변수를 만들었으니 이를 활용해서 다양한 변수에 따른 발언수를 비교해 보겠습니다. 전체 기간 동안 발언수가 가장 많은 10명은 누구인지, 요일별 발언수를 비교해보기도 하겠습니다. 이번 포스트에서는 범주형에 해당하는 닉네임, 오전과 오후, 요일에 대한 분석 위주로 설명드리겠습니다.
최종 결과 확인
발언 수가 많은 상위 10명
library(tidyverse)
library(scales)
library(ggthemes)
data %>% group_by(name) %>% summarise(n=n()) %>%
arrange(desc(n)) %>% slice(1:10) %>%
ggplot(aes(n, reorder(name, n), fill=name)) +
geom_col(show.legend = FALSE) +
geom_text(aes(label=comma(n)), hjust=1, size=4.5) +
scale_x_continuous(label=comma) +
theme_few() +
scale_fill_brewer(palette="Set3")+
labs(x = "발언 수", y = "", title = "발언 수가 많은 상위 10명")

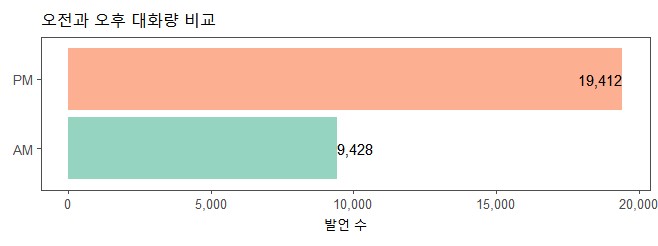
오전과 오후 대화량 비교
data %>% group_by(ampm) %>% summarise(n=n()) %>%
ggplot(aes(n, reorder(ampm, n), fill=ampm)) +
geom_col(show.legend = FALSE, alpha=0.7) +
geom_text(aes(label=comma(n)), hjust=c(0,1), size=4) +
scale_x_continuous(label=comma) +
theme_few() +
scale_fill_brewer(palette="Set2")+
labs(x = "발언 수", y = "", title = "오전과 오후 대화량 비교")+
theme(aspect.ratio=1/4)
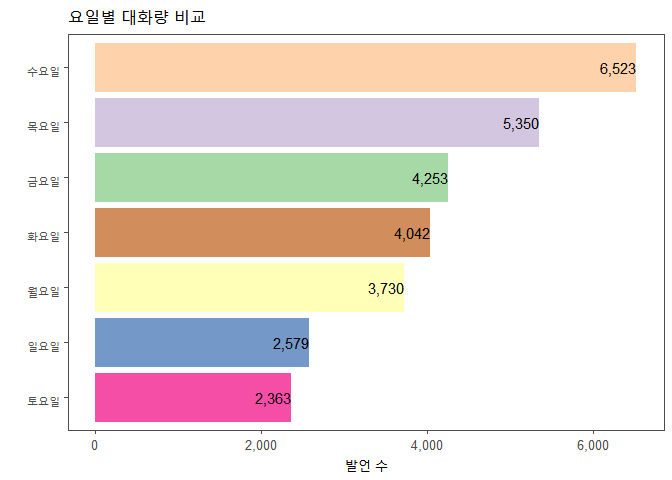
요일별 대화량 비교1
data %>% group_by(wday) %>% summarise(n=n()) %>%
ggplot(aes(n, reorder(wday, n), fill=wday)) +
geom_col(show.legend = FALSE, alpha=0.7) +
geom_text(aes(label=comma(n)), hjust=1, size=4) +
scale_x_continuous(label=comma) +
theme_few() +
scale_fill_brewer(palette="Accent")+
labs(x = "발언 수", y = "", title = "요일별 대화량 비교")
요일별 대화량 비교2
data %>% group_by(wday) %>% summarise(n=n()) %>%
mutate(wday=factor(wday, levels=c("월요일", "화요일", "수요일", "목요일", "금요일", "토요일", "일요일"))) %>%
ggplot(aes(wday, n, fill=wday)) +
geom_col(show.legend=F, alpha=0.7) +
geom_text(aes(label=comma(n)), hjust=0.5, vjust=1.5, nudge_y=0.5, size=4) +
scale_y_continuous(label=comma) +
theme_few() +
scale_fill_brewer(palette="Accent") +
labs(x="", y="발언 수", title = "요일별 대화량 비교")
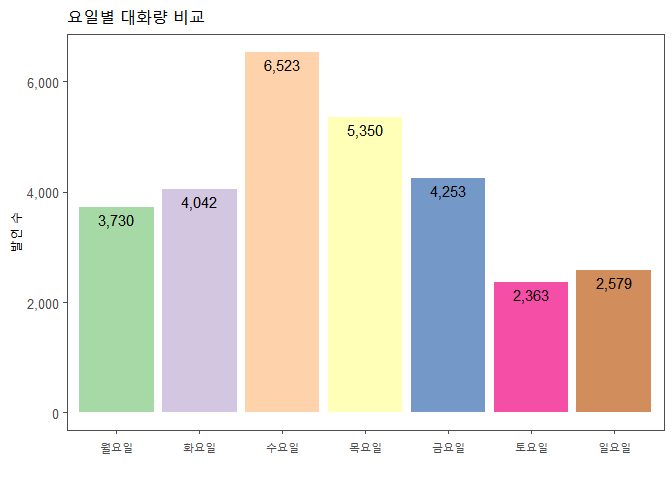
월별 발언수
rdata[c(1, nrow(rdata)), ] %>% pull(date)
## [1] "2019년 2월 27일 오후 11:02" "2022년 1월 15일 오후 7:49"
2019년과 2022년 날짜는 완벽하지 않습니다. 따라서 2020년과 2021년 데이터만 가지고 월별 발언수를 비교하는 것이 타당합니다.
data %>% filter(year %in% 2020:2021) %>%
group_by(month) %>% summarise(n=n()) %>%
mutate(month=factor(month, levels=12:1)) %>%
ggplot(aes(n, month, fill=month)) +
geom_col(alpha=0.7, show.legend=F) +
geom_text(aes(label=comma(n)), hjust=1, vjust=0.5, size=4) +
scale_x_continuous(label=comma) +
theme_few() +
labs(x="", y="발언 수", title = "월별 대화량 비교")

분기별 발언수1
data %>% filter(year %in% 2020:2021) %>%
group_by(quarter) %>% summarise(n=n()) %>%
ggplot(aes(quarter, n, fill=factor(quarter))) +
geom_col(alpha=0.5, show.legend=F) +
geom_text(aes(label=comma(n)), vjust=1.5, size=4) +
scale_y_continuous(label=comma) +
theme_few() +
scale_fill_brewer(palette="Dark2") +
labs(x="분기", y="발언 수", title = "분기별 대화량 비교") +
theme(aspect.ratio=2)

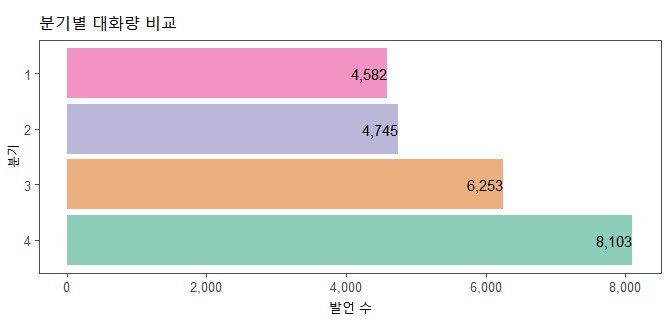
분기별 발언수2
data %>% filter(year %in% 2020:2021) %>%
group_by(quarter) %>% summarise(n=n()) %>%
mutate(quarter=factor(quarter, levels=4:1)) %>%
ggplot(aes(n, quarter, fill=quarter)) +
geom_col(alpha=0.5, show.legend=F) +
geom_text(aes(label=comma(n)), hjust=1, vjust=0.5, size=4) +
scale_x_continuous(label=comma) +
theme_few() +
scale_fill_brewer(palette="Dark2") +
labs(x="발언 수", y="분기", title = "분기별 대화량 비교") +
theme(aspect.ratio=3/8)
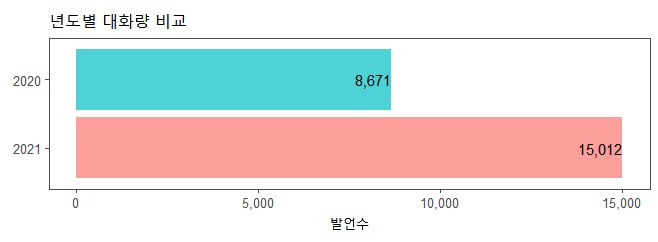
년도별 발언수
data %>% filter(year %in% 2020:2021) %>%
group_by(year) %>% summarise(n=n()) %>%
mutate(year=factor(year, levels=2021:2020)) %>%
ggplot(aes(n, year, fill=year)) +
geom_col(alpha=0.7, show.legend=F) +
geom_text(aes(label=comma(n)), hjust=1, vjust=0.5, size=4) +
scale_x_continuous(label=comma) +
theme_few() +
labs(x="발언수", y="", title = "년도별 대화량 비교") +
theme(aspect.ratio=1/4)
코드 설명
시각화를 위한 빈도수 만들기
data에서 문자로 된 변수는 name, ampm, wday가 있습니다. 각각 이름, 오전과 오후 구분, 요일 정보가 들어 있습니다. 이들 변수는 숫자가 아닌 문자로 구성되어 있는 범주형 변수입니다. 빈도수를 구할 변수를 group_by() 함수의 괄호 안에 입력하고 빈도수를 구하는 n() 함수를 summarise() 함수에 넣습니다. 이렇게 하면 원하는 변수의 범주별 빈도수를 구할 수 있고 ggplot() 함수를 이용하여 쉽게 시각화할 수 있습니다.
data에서 숫자로 된 변수 month, quarter, year 등의 변수도 있습니다. 이들 변수도 group_by(), n(), summarise() 함수로 빈도수를 구할 수 있습니다. 하지만 숫자로 구성된 연속형 변수는 막대그래프로 나타내는 것이 쉽지 않습니다. 막대 그래프로 그리기 위해서는 연속형 데이터를 범주형 데이터 취급하기 위해 factor() 함수를 사용해야 합니다.
막대 그래프 그리기
그래프를 설정하는 함수가 ggplot() 입니다. aes()는 그래프의 축을 설정한다고 보면 됩니다. 요일별 대화량을 비교했던 그래프를 기준으로 보통 ggplot(aes(x=wday, y=n))으로 표현해서 x축은 wday(요일)이 되고 y축은 n(빈도수)가 되도록 설정하죠. 그런데 영어의 경우 단어 순서에 따라 주어, 동사 등을 구분하는 습관이 있다보니 맨 앞에 쓴 것은 x축이고 그 다음은 y축에 해당한다고 생각합니다. 그러다보니 문법에 의해 x축 y축을 지정하지 않고 ggplot(aes(wday, n))으로 표현할 수도 있습니다. fill은 색을 칠하는 변수를 지정하면 됩니다.
ggplot(aes(wday, n, fill=wday))는 그래프의 축만 설정한 것이고요, 여기에 선이나 막대를 그려서 시각화합니다. 플러스(+) 기호와 함께 geom_col() 함수를 사용하면 막대 그래프를 그릴 수 있습니다. 참고로 범주형 데이터를 시각화할 때는 선그래프가 아닌 막대 그래프 형태로 나타내야 합니다. 물론 파이 그래프 등 다양하게 표현할 수도 있지만 일단 초보분들이 많을 거라 생각해서 막대 그래프로 통일해서 설명드리겠습니다. alpha는 파라미터들 중 하나인데 이는 투명도를 나타냅니다. 0은 완전 투명해서 하나도 안 보이는 것이고요, 1은 전혀 투명하지 않은 색이 됩니다. 0.8 정도면 약간 투명한 정도를 나타내죠. show.legend라는 파라미터는 범례를 표현할지의 여부를 나타내는데 F라고만 입력하면 FALSE로 인식해서 범례가 표시되지 않습니다. 축에 월요일부터 일요일까지 다 표시되는데 굳이 범례를 표시할 필요가 없습니다.
geom_text() 함수는 막대 그래프에 수치를 표현하라는 함수입니다. aes() 함수의 label이라는 파라미터를 지정해서 어떤 값을 표기할지 정합니다. n(빈도수)를 표현하는데 이를 comma() 함수로 감쌌죠. comma는 scales 패키지에서 지원하는데 1000단위로 콤마(,)를 찍어서 구분해줍니다. 예를 들어 10만이 있을 경우 콤마가 없으면 100000이 되는데 comma(100000) 하면 100,000으로 표현되어 가독성을 높여줍니다. hjust, vjust, nudge_y는 텍스트의 위치를 지정하는 파라미터이고, size는 글자 크기를 지정하는 파라미터입니다. 적절한 값을 입력해 보면서 원하는 위치에 원하는 크기로 표현될 수 있도록 조정할 수 있습니다.
scale_y_continuous() 함수를 이용해서 y축에 있는 값들도 1000을 넘어서면 콤마를 찍어서 구분하게 할 수 있고 경우에 따라서는 scale_x_continuous() 함수를 이용해서 x축에 있는 값들에 콤마를 찍을 수도 있습니다.
theme_few() 함수는 ggthemes 패키지에서 지원하는 여러 가지 형태 중 심플한 형태의 그래프를 지정해서 출력할 수 있습니다.
다른 그래프의 경우 scale_fill_brewer() 함수를 사용해서 색상을 원하는 것으로 지정할 수도 있습니다. 남들이 만들어 놓은 좋은 색상인데 개수가 많지 않아서 범주가 많게 되면 사용하기 힘들다는 단점이 있습니다. 우선 Set1, Set2, Set3를 바꿔가면서 색깔이 어떻게 바뀌는지 확인해보는 것을 권유합니다.
labs() 함수는 x축, y축, 그래프 제목 등을 임의로 지정할 수 있는 함수입니다.
시각화 팁
대체로 범주의 개수가 5개~7개 정도까지는 세로 막대 그래프가 예쁩니다. 범주의 개수가 4개 이하이거나 8개 이상일 경우 세로 막대보다는 가로 막대가 더 깔끔합니다. 특히 범주 이름이 긴 경우에는 가로 막대가 예쁘게 그려집니다.
예고
다음 글에서는 밀도함수를 통해 더 깊이 있게 분석해 보겠습니다.
댓글남기기