카카오톡 대화 전처리(1)
데이터 다운로드
카톡 대화 다운받는 방법
데스크탑 컴퓨터에서도 카카오톡 대화를 다운 받을 수 있습니다. 하지만 데이터 전처리를 쉽게 하려면 스마트폰에서 텍스트를 내보내는 것이 좋습니다.
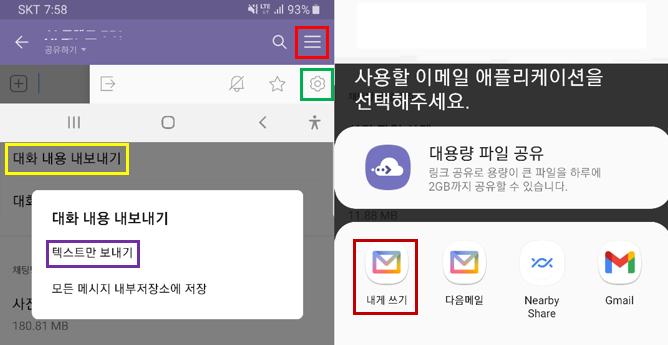
스마트폰에서 카톡방의 맨 오른쪽 위(빨간색)을 터치한 후 오른쪽 맨 아래쪽에 설정(초록색)을 터치합니다. 중간정도 보면 대화내용 내보내기(노란색)를 터치한 후 텍스트만 보내기(보라색)을 터치하면 위 그림의 오른쪽과 같이 어떤 형태로 텍스트를 내보낼지 선택할 수 있습니다. 본인이 원하는 방법(예, 갈색)를 이용하여 텍스트 파일을 받을 수 있습니다.
예제 파일 다운
예제 파일 다운 받아 연습해 볼 수 있습니다. 마우스 오른쪽 버튼으로 클릭해서 “다른 이름으로 링크 저장”해서 다운 받을 수 있습니다.
최종 결과 확인
다음과 같이 데이터를 전처리하면 됩니다. 참고로 실명은 기호로 대체하였습니다.
library(tidyverse)
(rdata <- read_file("KakaoTalkChatsSample.txt") %>% # txt 파일 읽어오기
strsplit("\r") %>% unlist() %>% # 같은 사람의 글은 한 줄로
gsub("\n", "", .) %>% as_tibble() %>% # 줄바꿈 없애기
filter(grepl("^\\d.*,.*:", value)) %>% # 숫자시작 , : 있는 것만
separate(value, into=c("date", "text"), sep=", ", extra="merge") %>% # 날짜와 글 분리
separate(text, into=c("name", "comment"), sep=" : ", extra="merge")) # 이름과 글 내용 분리
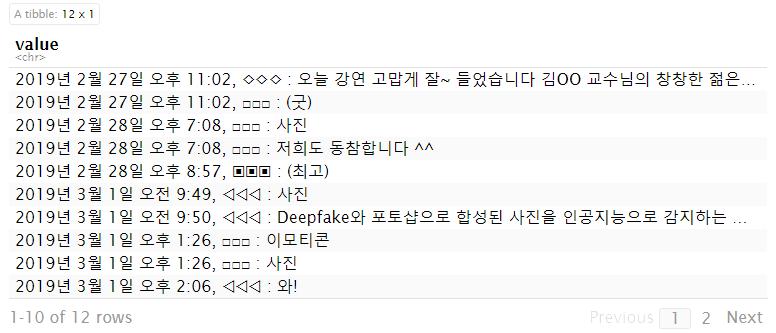
## # A tibble: 15 x 3
## date name comment
## <chr> <chr> <chr>
## 1 2019년 2월 27일 오후 11:02 ◇◇◇ 오늘 강연 고맙게 잘~ 들었습니다 김OO 교수님~
## 2 2019년 2월 27일 오후 11:02 □□□ (굿)
## 3 2019년 2월 28일 오후 7:08 □□□ 사진
## 4 2019년 2월 28일 오후 7:08 □□□ 저희도 동참합니다 ^^
## 5 2019년 2월 28일 오후 8:57 ▣▣▣ (최고)
## 6 2019년 3월 1일 오전 9:49 ◁◁◁ 사진
## 7 2019년 3월 1일 오전 9:50 ◁◁◁ Deepfake와 포토샵으로 합성된 사진을 인공지~
## 8 2019년 3월 1일 오후 1:26 □□□ 이모티콘
## 9 2019년 3월 1일 오후 1:26 □□□ 사진
## 10 2019년 3월 1일 오후 2:06 ◁◁◁ 와!
## 11 2019년 3월 2일 오후 8:22 △△△ https://www.youtube.com/watch?v=Iua-Z36J80A
## 12 2019년 3월 2일 오후 8:22 △△△ R에서 10줄로 구현한 keras입니다. ^^
코드 설명
Youtube 영상
영상이 편한 분은 영상을, 글이 편한 분은 다음 글을 참고하시면 되겠습니다.
여러 행 만들기
read_file() 함수를 이용해서 txt를 불러옵니다. 이 때 불러온 결과는 다음과 같이 단일 데이터를 가진 벡터가 됩니다.

strsplit() 함수에서 “\r”을 기준으로 데이터를 여러 개로 나눕니다. 그 후에 unlist() 함수를 적용하면 여러 데이터를 가진 하나의 벡터가 만들어집니다.

“\n”을 기준으로 나누게 되면 카톡을 작성할 때 줄바꿈해서 작성한 글의 경우 여러 개의 데이터로 나눠지게 됩니다. 줄바꿈을 사용해서 작성한 글도 한 사람이 작성했으면 하나의 데이터로 묶이게 만들어야 하는데 그렇게 하기 위해서는 “\n”이 아닌 “\r”을 기준으로 데이터를 분리해야 합니다. 문제는 list 형태로 나눠지기 때문에 unlist() 함수를 통해 여러 개의 데이터를 가진 벡터로 만들어야 합니다. 여기서 또 다른 문제가 생기는데 “\r”을 기준으로 줄바꿈한 후 바로 다음 글이 이어지다보니 날짜 앞에 “\n”이 놓이게 됩니다. 그래서 gsub() 함수를 이용해서 “\n”을 “”로 만들어서 없애주어야 합니다.

이렇게 해서 만든 데이터를 as_tibble() 함수를 이용해서 tibble 형태의 데이터로 만듭니다. 이 때 자동으로 value라는 변수로 묶이게 됩니다.

유효한 행만 선택
지금까지 전처리된 데이터를 살펴보면 대부분의 데이터는 글을 작성한 “일시, 유저이름 : 작성 내용” 형태로 구성되어 있습니다. 어떤 데이터는 숫자가 아닌 한글로 시작하는 문구도 있고 날짜가 바뀌었을 때 처음 글을 쓴 시각만 기록된 것도 있습니다. 실제 구성원들이 작성한 글을 분석하는 것이 의미가 있기 때문에 이런 내용들은 분석에서 제외하는 것이 좋습니다. 이를 위해 filter() 함수를 통해 일시, 유저이름, 작성내용이 모두 있는 조건을 만족하는 데이터만 선택해야 합니다. 일시는 숫자로 시작하는 특징이 있으며 일시와 유저 이름 사이에는 콤마(,)가 들어 있습니다. 그리고 유저이름과 작성 내용 사이에는 콜론(:)이 있습니다. 따라서 숫자로 시작하며, 콤마(,)가 있고, 콜론(:)이 있는 데이터만 선택해야 합니다.
grepl() 함수는 특정 변수에 지정한 내용이 있는지의 여부를 TRUE, FALSE 형태로 출력합니다. 이를 이용해 조건에 맞는(TRUE) 데이터만 선택할 수 있습니다. 정규표현식을 통해 원하는 조건에 해당하는 글을 선택할 수 있습니다. 다소 어려울 수 있어 차근 차근 설명하면 다음과 같습니다. “\\d”는 숫자를 의미합니다. 이를 활용하면 숫자가 포함된 데이터만 선택할 수도 있습니다. 그 앞에 “^”를 추가해서 “^\\d”로 표시하면 숫자로 시작하는지의 여부를 나타냅니다. 이를 활용하면 첫 글자가 숫자로 시작하는 데이터를 선택할 수 있습니다. “.*“는 “그리고”(보통은 & 기호를 사용함)에 해당합니다. 참고로 “또는”에 해당하는 기호는 |입니다. 그래서 숫자로 시작해야하고, 콤마(,)를 가지고 있어야 하는 데이터만 선택하려면 “^\\d.*,”로 표기하면 됩니다. 여기에 콜론(:)도 반드시 포함해야 한다는 조건을 추가하면 “^\\d.*,.*:”이 됩니다. 따라서 grepl(“^\\d.*,.*:”, value) 함수를 실행시키면 value라는 변수에서 숫자로 시작하고, 콤마(,), 콜론(:)을 모두 포함하는 데이터인 경우 TRUE를, 하나라도 조건을 만족하지 않으면 FALSE를 출력합니다. 이를 filter() 함수로 감싸주면 TRUE에 해당하는 데이터만 선택하게 됩니다.
일시, 유저, 내용 분리
separate() 함수는 특정 조건에 맞는 글자를 기준으로 변수를 분리해주는 기능을 합니다. 우선 “일시”와 나머지 내용을 구분하면 다음과 같습니다.

separate(value, into=c(“date”, “text”), sep=“,”)라고 쓰면 value에 있는 텍스트에서 콤마(,)와 띄어쓰기(“,”)를 기준으로 왼쪽과 오른쪽을 각각 date, text로 명명된 변수로 분리하라는 뜻이 됩니다. 그런데 사용자가 콤마(,)를 사용해서 글을 작성한 경우 여러 개의 콤마(,)가 있을 수 있습니다. 이 때 맨 처음에 있는 콤마(,)를 기준으로 두 개의 변수로 분리하고 나머지 콤마(,)는 분리하지 말고 하나로 합쳐서 표현하라는 의미로 extra=“merge”를 추가합니다. 같은 원리로 그렇게 만들어진 text를 콜론(:)을 기준으로 name, comment로 분리하라는 함수가 separate(text, into=c(“name”, “comment”), sep=“ : ”, extra=”merge”) 입니다.

전처리 결과 확인
이러한 전처리 과정은 파이프 라인(%>%)을 이용해서 순차적으로 처리해서 rdata(습관적으로 raw data를 이와같이 표현함)에 저장합니다. 그리고 그 전체를 괄호()로 묶어주면 그렇게 전처리 결과를 바로 확인할 수 있습니다. 보통은 전처리한 결과를 rdata에 저장한 후 rdata를 한 번 더 써서 그 결과를 확인하는데 R에서는 전체를 괄호로 묶어주면 굳이 rdata를 한 번 더 써주지 않아도 적용 결과를 확인할 수 있습니다.
예고
다음 글에서는 date를 조작해서 년도, 월, 요일, 오전 오후, 시간 등 텍스트 마이닝할 때 분석 기준이 되는 변수들을 분리해 내는 전처리 과정을 살펴볼 예정입니다.
댓글남기기