카카오톡 단어 분석2 (단어간 먼 거리, 네트워크 분석)
미션 이해
사람들이 가장 많이 사용한 단어는 무엇인지 알아보고 그 단어들과 함께 사용한 단어는 무엇인지 단어간 상관관계를 통해 살펴봅니다. tm 패키지를 이용하여 dtm(document term matrix)를 만들어 단어 빈도수와 단어간 상관관계를 살펴봅시다.
최종 결과 확인
형태소 분석하기
pacman::p_load(scales, ggthemes, ggridges, # 시각화 관련 패키지
forecast, # 시계열 예측 관련 패키지
RHINO, tm, RWeka, tidytext, tidystm, # 텍스트 마이닝
igraph, ggraph, tidygraph, wordcloud2, # 텍스트 마이닝 시각화
tidymodels, textrecipes, LiblineaR, themis, # 머신러닝
lubridate, magrittr, tidyverse) # 데이터 전처리 관련 패키지
initRhino()
rdata <- read_file("../data/KakaoTalkChats.txt") %>% # txt 파일 읽어오기
strsplit("\r") %>% unlist() %>% # 같은 사람의 글은 한 줄로
gsub("\n", "", .) %>% as_tibble() %>% # 줄바꿈 없애기
filter(grepl("^\\d.*,.*:", value)) %>% # 숫자시작 , : 있는 것만
separate(value, into=c("date", "text"), sep=", ", extra="merge") %>% # 날짜와 글 분리
separate(text, into=c("name", "comment"), sep=" : ", extra="merge") # 이름과 글 내용 분리
data <- rdata %>%
mutate(date=gsub("년 ", "-", gsub("월 ", "-", gsub("일 ", " ", date)))) %>%
mutate(date=gsub("오전", "AM", gsub("오후", "PM", date))) %>%
mutate(date=parse_date_time(date, c("%Y-%m-%d %p %H:%M"))) %>% # 날짜 형식으로
mutate(year=year(date), quarter=quarter(date), month=month(date), # 년, 분기, 월 변수 만들기
wday=weekdays(date), yday=yday(date), hour=hour(date), # 요일, 일수, 시간 변수 만들기
ampm=ifelse(hour(date)<12, "AM", "PM")) %>% # 오전 오후 변수 만들기
select(year:ampm, name, comment) %>% # 주요 변수 선택
mutate(형태소=comment %>% sapply(getMorph, "NV") %>% # 명사, 동사, 형용사만 선택
sapply(paste, collapse=" ")) # 형태소 분석 결과 합치기
inspect(word_dtm <- data$형태소 %>% na.omit() %>% VectorSource() %>% VCorpus() %>%
DocumentTermMatrix(control=list(wordLengths=c(2,Inf))))
## <<DocumentTermMatrix (documents: 28840, terms: 15273)>>
## Non-/sparse entries: 155190/440318130
## Sparsity : 100%
## Maximal term length: 10
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs ai 감사 데이터 드리 만들 발표 사람 사진 생각 프렌즈
## 12402 0 0 0 0 3 0 3 0 0 0
## 13660 1 2 0 0 0 3 5 0 0 0
## 13825 0 0 0 0 0 1 0 2 0 0
## 13920 0 0 0 0 0 3 0 0 0 0
## 14354 1 0 0 0 0 2 1 0 0 0
## 14372 1 0 0 0 0 0 1 0 0 0
## 14401 2 0 0 0 0 0 1 0 0 0
## 14753 0 0 0 0 0 1 2 1 0 0
## 14781 0 0 0 0 0 2 1 0 0 0
## 6778 8 0 1 1 0 1 0 0 0 1
rdata는 전처리가 거의 없는 데이터이고 data는 EDA나 머신러닝, 텍스트 마이닝 등에 사용될 범용적인 데이터입니다. data 파일의 comment의 글을 형태소 분석하여 “형태소”라는 변수를 추가로 만듭니다. 형태소는 명사, 동사, 형용사에 해당하는 것만 수집하며 나중에 토픽 분석을 쉽게 할 수 있도록 tibble 형태로 유지합니다.
getMorph() 함수는 RHINO 패키지에서 지원하는 형태소 분석 함수입니다. “NV”는 명사와 동사, 형용사를 의미합니다. 분석결과는 list 형태로 출력이 되는데 이를 paste() 함수를 사용해서 공백을 추가하여 하나의 vector로 만들어서 “형태소”라는 변수로 저장합니다.
VectorSource() 함수와 VCorpus() 함수를 써서 말뭉치를 만들고 DocumentTermMatrix() 함수로 dtm을 만듭니다.
차원 축소 분석(먼 거리의 단어 시각화)
word_dtm %>% removeSparseTerms(0.997) %>% as.matrix() %>% # 희소 단어 제거
prcomp(scale=T) %>% extract2(2) %>% data.frame() %>% # 차원축소
rownames_to_column("term") %>% select(term, PC1, PC2, PC3) %>% # 첫번째 차원 선택
filter(row_number(desc(PC2))<=10 | row_number(PC2)<=10) %>% # 상위 10개와 하위 10개 단어 선택
mutate(division=ifelse(PC2>0, "A", "B")) %>%
ggplot(aes(reorder(term, -PC2), PC2, fill=division)) +
geom_col(show.legend=F, alpha=0.8) +
theme(axis.text.x=element_text(angle=90, hjust=1, vjust=0.5, size=12, color = "black"),
axis.ticks.x=element_blank()) +
labs(x="Terms", y="Relative importance in principle component")

PCA 분석 결과를 바탕으로 양의 값 중에 큰 값 10개에 해당하는 단어와 음의 값 중 작은 값 10개에 해당하는 단어를 비교합니다. 경우에 따라서는 긍정적인 내용과 부정적인 내용, 보수적인 내용과 진보적인 내용 등 거리가 먼 단어들을 찾아내 시각화할 수 있습니다.
데이터가 많은 경우 계산에 필요한 시간이 기하급수적으로 늘어납니다. removeSparseTerms() 함수를 통해 300개 전 후의 단어가 선정되도록 합니다. removeSparseTerms() 함수는 사용 빈도수가 작은 단어들을 제외시키는데 0.997이면 0.3% 미만의 빈도를 갖는 단어를 제외한다는 뜻이 됩니다. prcomp() 함수가 차원축소(PCA, Principal Components Analysis) 함수입니다. extract2() 함수는 magrittr 패키지에서 지원하는 함수로 리스트 형태의 데이터 중 원하는 데이터를 뽑아낼 수 있습니다. 위 코드는 2번째 데이터를 뽑아내는데 이것이 차원축소한 결과 데이터입니다. rownames_to_column() 함수를 써서 행의 이름으로 된 단어를 term이라는 변수(열)의 이름으로 뽑아내고 분석을 위해 단어(term), PC1, PC2, PC3 를 선택합니다. 첫 번째 차원이 PC1이고 PC2는 두 번째 차원을 의미합니다. desc() 함수를 써서 내림차순으로 정렬했을 때 상위 10개와 오름차순으로 정렬했을 때 상위 10개를 선택합니다. division이라는 변수를 만들어 양수인 값을 A, 음수인 값을 B로 선정합니다.
x축은 단어(term)으로 설정하되 차원 축소된 값을 기준으로 정렬합니다. 마이너스(-)가 붙으면 그래프의 원점(왼쪽 부분)에 값이 큰 단어가 배치되고 오른쪽으로 갈수록 값이 작아지는 순으로 배치됩니다. y축은 차원 축소된 값을 명기하고 플러스 값과 마이너스 값으로 그룹화된 division을 기준으로 색을 칠합니다.
단어간 네트워크 분석을 위한 준비
word_tokenizer <- function(x) NGramTokenizer(x, Weka_control(min=2, max=2))
word_dtm_bigram <- data %>% pull(형태소) %>%
VectorSource() %>% VCorpus() %>%
DocumentTermMatrix(control=list(tokenize=word_tokenizer))
word_bigram <- tidy(word_dtm_bigram) %>% group_by(term) %>%
summarise(count=sum(count)) %>% arrange(desc(count)) %>%
separate(term, c("from", "to"), sep=" ") %>%
# filter(str_length(from)>=2 & str_length(to)>=2) %>%
filter(count>=120)
연속된 두 단어를 바탕으로 연속된 두 단어의 빈도수를 선의 굵기로 표현하고 단어와 단어를 연결해주는 중심 역할을 하는 단어를 알아보기 위해 네트워크 분석을 실시합니다.
Weka 패키지에서 지원하는 NGramTokenizer() 함수를 이용하여 n-gram을 만듭니다. 2-gram은 bigram이라고 부르며 연속된 두 단어를 수집하며 3-gram은 trigram이라고 부르며 연속된 3단어를 가리킵니다. 복잡한 분석에서는 연속된 3단어 이상도 사용하지만 여기에서는 Weka_control을 최솟값도 2, 최댓값도 2로 선정하여 연속된 2단어만 분석하였습니다. 연속된 두 단어만 분석하는 것을 word_tokenizer 함수로 저장합니다.
dtm 문서를 만들 때 연속된 두 단어만 수집하기 위해 tokenize를 word_tokenizer 함수로 지정합니다.
bigram의 빈도수를 summarise() 함수와 sum() 함수를 이용하여 구하고 내림차순으로 정렬합니다. 네트워크 분석을 위해 연속된 두 단어를 “from”과 “to”로 분리하고 적절한 시각화를 위해 최소 빈도수를 정합니다. 보통 30~40개 정도로 만들면 시각화 했을 때 그럴듯하게 보입니다. 여기서는 사용 빈도수가 120회 이상일 때로 정하였고 그렇게 할 때 35개 정도가 선정되었다.
단어간 네트워크 분석 결과 시각화
word_bigram %>% as_tbl_graph(directed=F) %>%
mutate(pagerank=centrality_pagerank(), group=group_infomap()) %>%
ggraph(layout="fr") +
geom_edge_link(aes(width=count), color='gray50', alpha=0.5) +
geom_node_point(aes(color=factor(group), size=pagerank)) +
geom_node_text(aes(label=name), size=4.5, repel=T) +
scale_edge_width(range = c(0.2, 2)) +
theme_graph() + theme(legend.position='none')
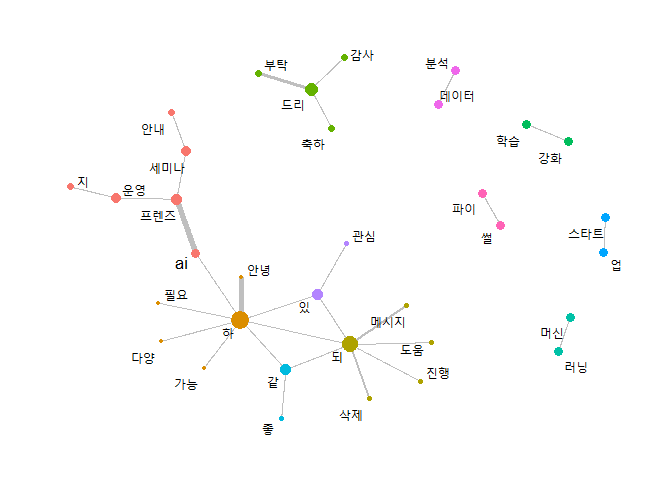
120회 이상 반복 언급된 단어 35개쌍을 바탕으로 단어간 네트워크를 시각화하였습니다.
tidygraph 패키지에서 지원하는 as_tbl_graph() 함수를 써서 Node와 Edge를 계산합니다. 네트워크를 분석할 때 중심성을 측정하는 방법으로 여러 가지가 있는데 여기에서는 centrality_pagerank() 함수를 써서 페이지랭크 방식을 사용합니다. 페이지랭크는 구글에서 검색 결과를 노출할 때 사용하는 알고리즘으로 꽤 유명한 방법입니다. group_infomap() 함수를 사용하여 커뮤니티 구조를 기반으로 노드 및 에지를 그룹화합니다.
ggraph() 함수를 이용하여 네트워크 분석 결과를 시각화합니다. geom_edge_link() 함수로 점과 점을 이을 선의 특성을 결정합니다. 선의 폭을 빈도수로 설정하였습니다. geom_node_point() 함수를 써서 단어를 표현할 점의 특성을 정합니다. 점의 크기를 pagerank에 의한 중심성 정도를 시각화합니다. geom_node_text() 함수를 써서 단어를 표시하고, scale_edge_width() 함수로 적절한 범위 내에서 선의 크기를 시각화하여 보기 좋게 만듭니다. theme_graph() 테마를 설정하여 바탕화면을 흰색으로 만들고 theme() 함수로 범례를 삭제합니다.
예고
카카오톡 글에 대해 토픽 분석을 실시할 예정입니다. LDA처럼 토픽들 사이에 상관관계가 없다고 가정하고 토픽분석할 수도 있지만 보다 현실성 있게 토픽들 사이에도 상관관계가 있음을 가정한 STM 방식으로 토픽분석하여 분석 결과를 시각화하겠습니다.
댓글남기기