데이콘(생육 환경 최적화 경진대회) : Outlier1
최종결과 : blue LED와 청색광추정광량 사이의 관계
LED와 청색광추정광량
#### 1. 분석 준비 ####
pacman::p_load(ggpmisc, tidyverse) # 데이터 전처리 관련 패키지
#### 2. 기본 데이터 로딩 ####
meta_train <- list.files(path="train_meta", full.names = TRUE) %>%
lapply(function(x) read_csv(x, show_col_types = F) %>%
mutate(img_name=x, .before=1)) %>% bind_rows()
train_meta <- train_meta %>% mutate(img_name=str_remove_all(img_name, "train_meta/|.csv")) %>%
rename("whiteLED"='화이트 LED동작강도', "redLED"='레드 LED동작강도', "blueLED"='블루 LED동작강도')
test_meta <- list.files(path="test_meta", full.names = TRUE) %>%
lapply(function(x) read_csv(x, show_col_types = F) %>%
mutate(img_name=x, .before=1)) %>% bind_rows()
test_meta <- test_meta %>% mutate(img_name=str_remove_all(img_name, "test_meta/|.csv")) %>%
rename("whiteLED"='화이트 LED동작강도', "redLED"='레드 LED동작강도', "blueLED"='블루 LED동작강도')
#### 3. 이상치 점검 ####
#### 가. blueLED와 청색광추정광량 ####
data <- train_meta %>% mutate(group="train") %>%
bind_rows(test_meta %>% mutate(group="test")) %>%
select(img_name, group, whiteLED:blueLED, 총추정광량:청색광추정광량) %>%
group_by(img_name, group) %>% summarise_all(mean, na.rm=T)
data %>% ggplot(aes(blueLED, 청색광추정광량)) +
geom_point() + theme_bw() + facet_wrap(~group, scales="free") +
geom_smooth(method=lm, formula=y~0+x, alpha=0.2, se=F, show.legend=FALSE) +
stat_poly_eq(aes(label = paste(..eq.label.., ..adj.rr.label.., sep = "~~~~")),
formula = y~0+x, parse = TRUE)+
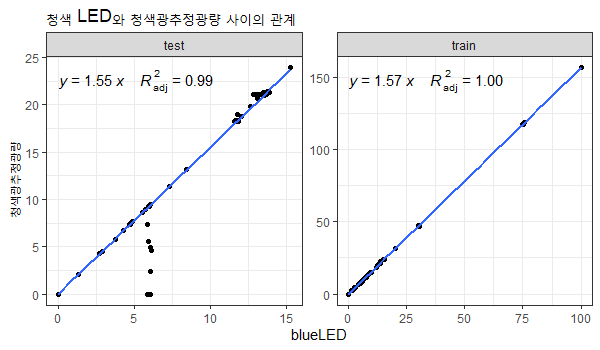
labs(title="청색 LED와 청색광추정광량 사이의 관계")
train 데이터를 살펴보면 blueLED와 청색광추정광량은 거의 완벽한 선형관계임을 알 수 있습니다. 하지만 test 데이터를 살펴보면 일부 데이터가 그렇지 않은 것을 확인할 수 있습니다. blueLED값에 1.57을 강제적으로 곱해줄 필요가 있어 보입니다.
redLED와 적색광추정광량1
data %>% ggplot(aes(redLED, 적색광추정광량)) +
geom_point() + theme_bw() + facet_wrap(~group, scales="free") +
geom_smooth(method=lm, formula=y~0+x, alpha=0.2, se=F, show.legend=FALSE) +
stat_poly_eq(aes(label = paste(..eq.label.., ..adj.rr.label.., sep = "~~~~")),
formula = y~0+x, parse = TRUE)+
labs(title="적색 LED와 적색광추정광량 사이의 관계")
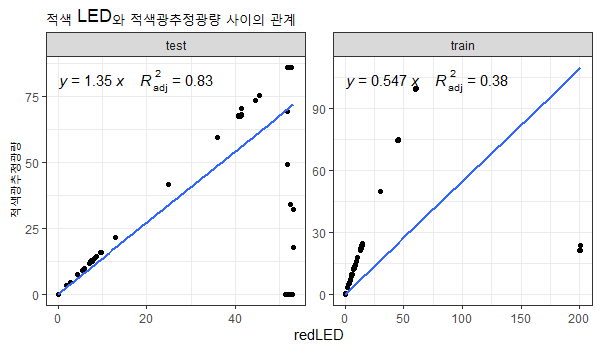
적색의 경우 회귀분석에서의 기울기를 바꿀 정도로 이상치가 많다는 것을 알 수 있습니다. 그래프 상에서의 점은 1개이지만 여러 개가 중첩된 것으로 이해하시면 됩니다. 이상치를 제외했을 때 적색 LED와 적생광추정광량 사이의 관계를 명확하게 알아야합니다.
redLED와 적색광추정광량2
train_meta %>% filter(grepl("CASE19", img_name)) %>%
ggplot(aes(redLED, 적색광추정광량)) +
geom_point() + theme_bw() +
geom_smooth(method=lm, formula=y~0+x, alpha=0.2, se=F, show.legend=FALSE) +
stat_poly_eq(aes(label = paste(..eq.label.., ..adj.rr.label.., sep = "~~~~")),
formula = y~0+x, parse = TRUE)+
labs(title="적색 LED와 적색광추정광량 사이의 관계")
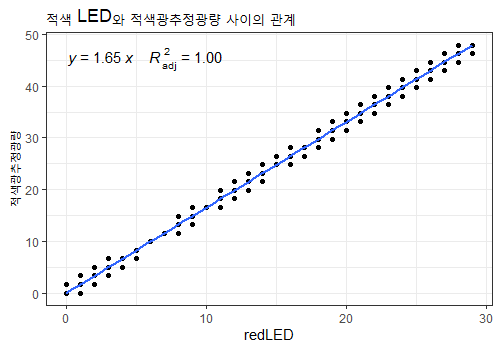
CASE19에 해당하는 데이터의 경우 이상치가 없습니다. 해당 데이터만 선택해서 그래프를 그려보면 둘 사이의 관계식을 알 수 있습니다. 소수 둘째 자리까지만 표시되는데 그 이상 더 자세하게 알고 싶으면 어떻게 해야할까요?
redLED와 적색광추정광량3
train_meta %>% filter(grepl("CASE19", img_name)) %>%
lm(적색광추정광량~0+redLED, .) %>% summary()
## Call:
## lm(formula = 청색광추정광량 ~ 0 + blueLED, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.57053 -0.00320 -0.00052 0.00000 1.56650
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## blueLED 1.566603 0.000132 11869 <2e-16 ***
## ---
## Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
##
## Residual standard error: 0.2281 on 7076 degrees of freedom
## (결측으로 인하여 123개의 관측치가 삭제되었습니다.)
## Multiple R-squared: 0.9999, Adjusted R-squared: 0.9999
## F-statistic: 1.409e+08 on 1 and 7076 DF, p-value: < 2.2e-16
Estimate를 읽으면 됩니다. 1.566603 입니다. 위 코드에서 redLED를 blueLED, whiteLED로 바꾸고 적색광추정광량을 청색추정광량, 백색추정광량으로 바꾸면 각각의 LED와 추정광량 사이의 관계를 보다 엄밀하게 추정할 수 있습니다.
총추정광량
data %>%
filter(!is.na(백색광추정광량) & !is.na(적색광추정광량) &
!is.na(청색광추정광량) & !is.na(총추정광량)) %>%
mutate(sum=백색광추정광량+적색광추정광량+청색광추정광량) %>%
ggplot(aes(sum, 총추정광량)) + geom_point() +
geom_smooth(method=lm, formula=y~0+x, alpha=0.2, se=F, show.legend=FALSE) +
stat_poly_eq(aes(label = paste(..eq.label.., ..adj.rr.label.., sep = "~~~~")),
formula = y~0+x, parse = TRUE)
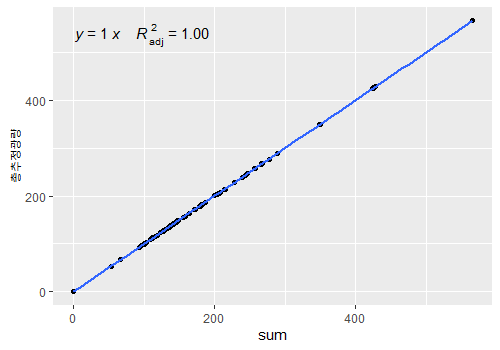
총추정광량은 백색광추정광량, 적색광추정광량, 청색광추정광량의 합이라는 것을 확인할 수 있습니다.
이상치 처리
train_meta_fill <- train_meta %>%
mutate(청색광추정광량=1.5666*blueLED,
적색광추정광량=1.6548*redLED,
백색광추정광량=3.0939*whiteLED) %>%
mutate(총추정광량=백색광추정광량+적색광추정광량+청색광추정광량) %>%
select(img_name, 내부온도관측치, 내부습도관측치, CO2관측치, EC관측치,
최근분무량, 총추정광량, 백색광추정광량, 적색광추정광량, 청색광추정광량) %>%
rename(temp=2, humi=3, CO2=4, EC=5, water=6, light=7, light_w=8, light_r=9, light_b=10) %>%
mutate(light_b=ifelse(is.na(light_b) & !is.na(light) & !is.na(light_w) & !is.na(light_r),
light-light_w-light_r, light_b)) %>%
group_by(img_name) %>% summarise_all(list(mean), na.rm=T)
train_meta_fill
## # A tibble: 1,592 x 10
## img_name temp humi CO2 EC water light light_w light_r light_b
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 CASE01_01 22.2 77.7 487. 19.6 0 955. 621. 333. 0.366
## 2 CASE01_02 23.0 77.6 480. 20.9 0 954. 621. 332. 0.367
## 3 CASE01_03 22.9 77.5 489. 20.7 0 953. 621. 332. 0.367
## 4 CASE01_04 21.0 80.1 481. 18.2 0 949. 619. 331. 0.366
## 5 CASE01_05 21.9 81.3 491. 19.4 0 954. 621. 333. 0.366
## 6 CASE01_06 24.3 80.2 496. 23.1 0 954. 622. 332. 0.365
## 7 CASE01_07 24.5 81.5 513. 23.4 0 954. 621. 333. 0.366
## 8 CASE01_08 24.6 82.4 514. 23.6 0 950. 620. 332. 0.367
## 9 CASE01_09 25.4 83.5 493. 23.9 0 952. 621. 332. 0.365
## 10 CASE02_01 21.9 82.9 522. 19.9 0 953. 620. 332. 0.359
## # ... with 1,582 more rows
적절하게 이상치가 잘 채워져서 평균을 구했습니다. 같은 CASE의 경우 대체적으로 평균 환경이 일치한다는 것을 알 수 있습니다. 문제는 CASE01의 경우 water(최근 물 분부량)이 0입니다. 개인적으로 이상치라고 생각해서 평균 물분무량이 0인 데이터는 제외하고 분석하고 있습니다.
댓글남기기